tokenspeed
Introduction: TokenSpeed is a speed-of-light LLM inference engine.
Tags:

TokenSpeed is a speed-of-light LLM inference engine designed for agentic workloads, with TensorRT-LLM-level performance and vLLM-level usability. Our goal is to be the most performant inference engine for production agentic workloads.
Core components:
- Modeling layer: local-SPMD design with a static compiler that generates collective communication from module-boundary placement annotations, so users do not hand-write parallelism logic.
- Scheduler: C++ control plane and Python execution plane. Request lifecycle, KV cache ownership, and overlap timing are encoded as a finite-state machine, with safe KV resource reuse enforced by the type system at compile time.
- Kernels: pluggable, layered kernel system with a portable public API and a centralized registry including one of the fastest MLA (Multi-head Latent Attention) implementations on Blackwell for agentic workload.
- Entrypoint: SMG-integrated AsyncLLM for low-overhead CPU-side request handling.
- [2026/07] TML Inkling at Day 0: FP4 Inference on NVIDIA and AMD with TokenSpeed. [blog]
- [2026/06] Deep dive into the design and optimization of TokenSpeed-Kernel. [blog]
- [2026/05] 🚀 TokenSpeed hits 580 TPS on Qwen3.5-397B-A17B for agentic workloads. [blog]
- [2026/05] TokenSpeed announced — a speed-of-light LLM inference engine for agentic workloads. [blog]
Blogs and Talks
For technical blogs, conference talks, and engineering articles from LightSeek Foundation, visit the LightSeek Blog.
Performance Comparison
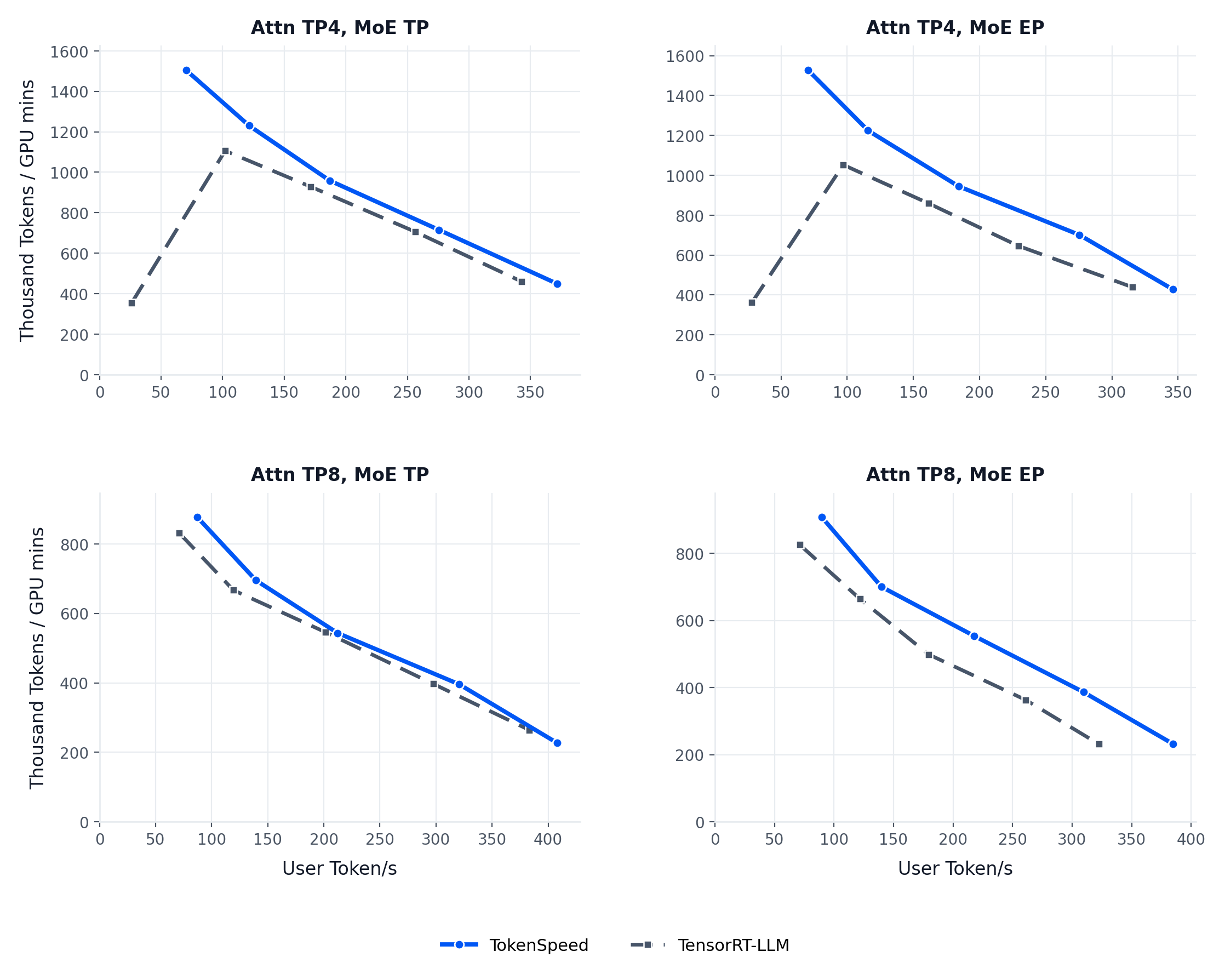
Documentation
Start here:
