EasyScheduler
![]()
![]()

![]()
About
Apache DolphinScheduler is a modern data orchestration platform that empowers agile, low-code development of high-performance workflows. It is dedicated to handling complex task dependencies in data pipelines and provides a wide range of built-in job types out of the box.
Key features for DolphinScheduler are as follows:
- Easy to deploy, providing four deployment modes including Standalone, Cluster, Docker, and Kubernetes.
- Easy to use, workflows can be created and managed via Web UI, Python SDK or Open API
- Highly reliable and high availability, with a decentralized, multi-master and multi-worker architecture and native support for horizontal scaling.
- High performance, its performance is several times faster than other orchestration platforms, and it is capable of handling tens of millions of tasks per day
- Cloud Native, DolphinScheduler supports orchestrating workflows across multiple clouds and data centers, and allows custom task types
- Workflow Versioning, provides version control for both workflows and individual workflow instances, including tasks.
- Flexible state control of workflows and tasks, supports pausing, stopping, and recovering them at any time.
- Multi-tenancy support
- Additional features, backfill support(Web UI native), permission control including project and data source etc.
QuickStart
- For quick experience
- Want to start with standalone
- Want to start with Docker
- For Kubernetes
- For Terraform
User Interface Screenshots
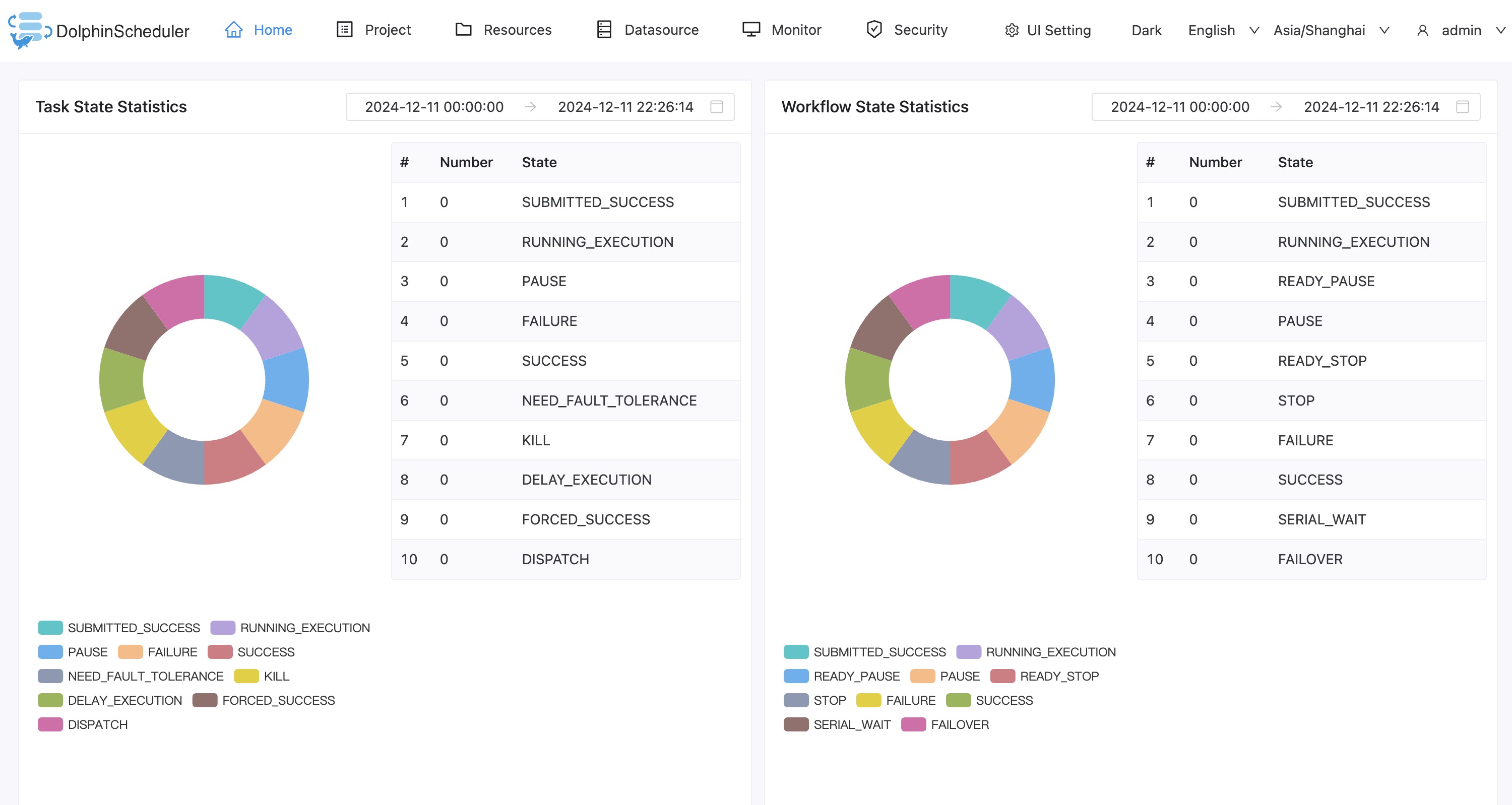
Homepage: Project and workflow overview, including the latest workflow instance and task instance status statistics.
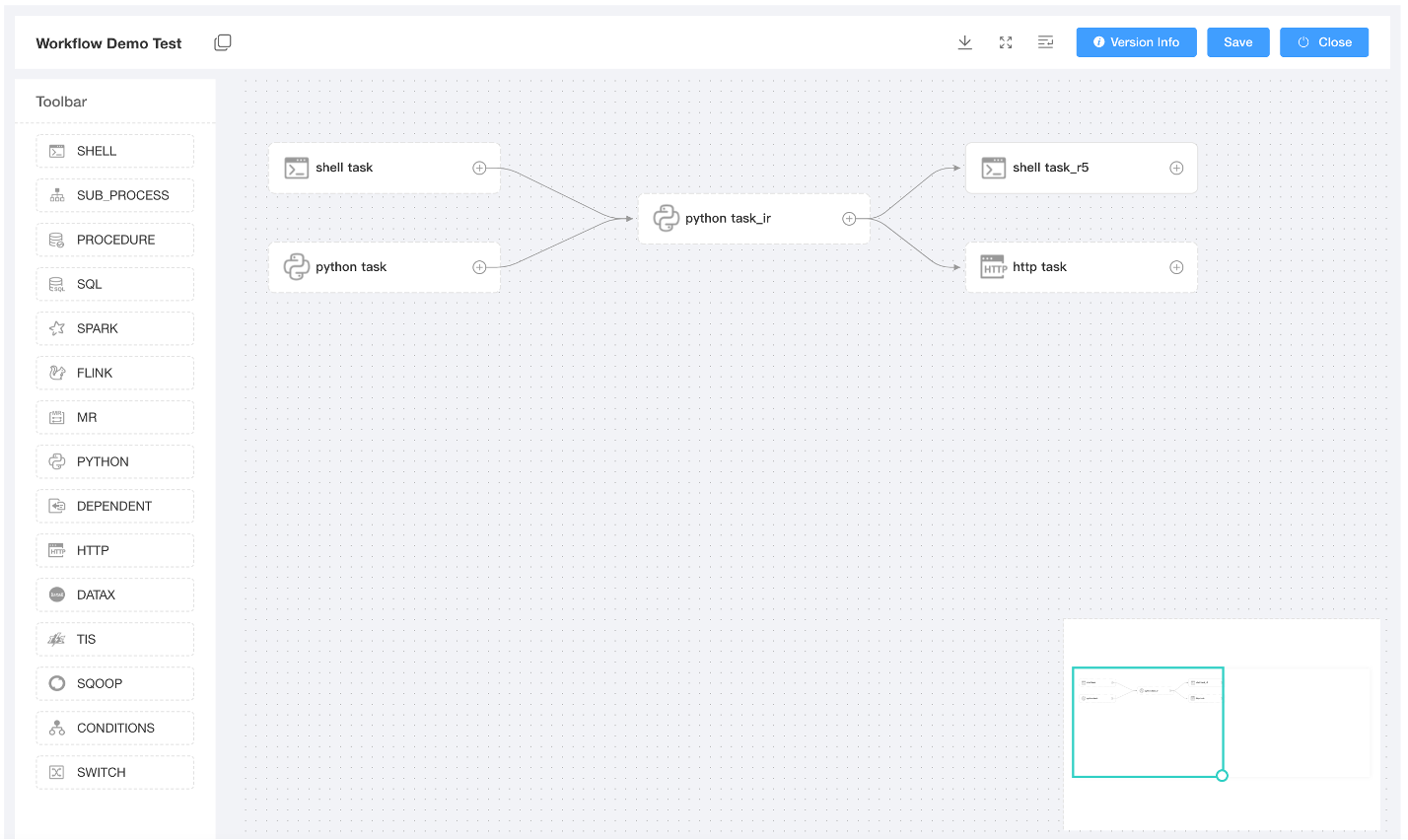
Workflow Definition: Create and manage workflows by drag and drop, easy to build and maintain complex workflows, support a wide range of tasks out of box.
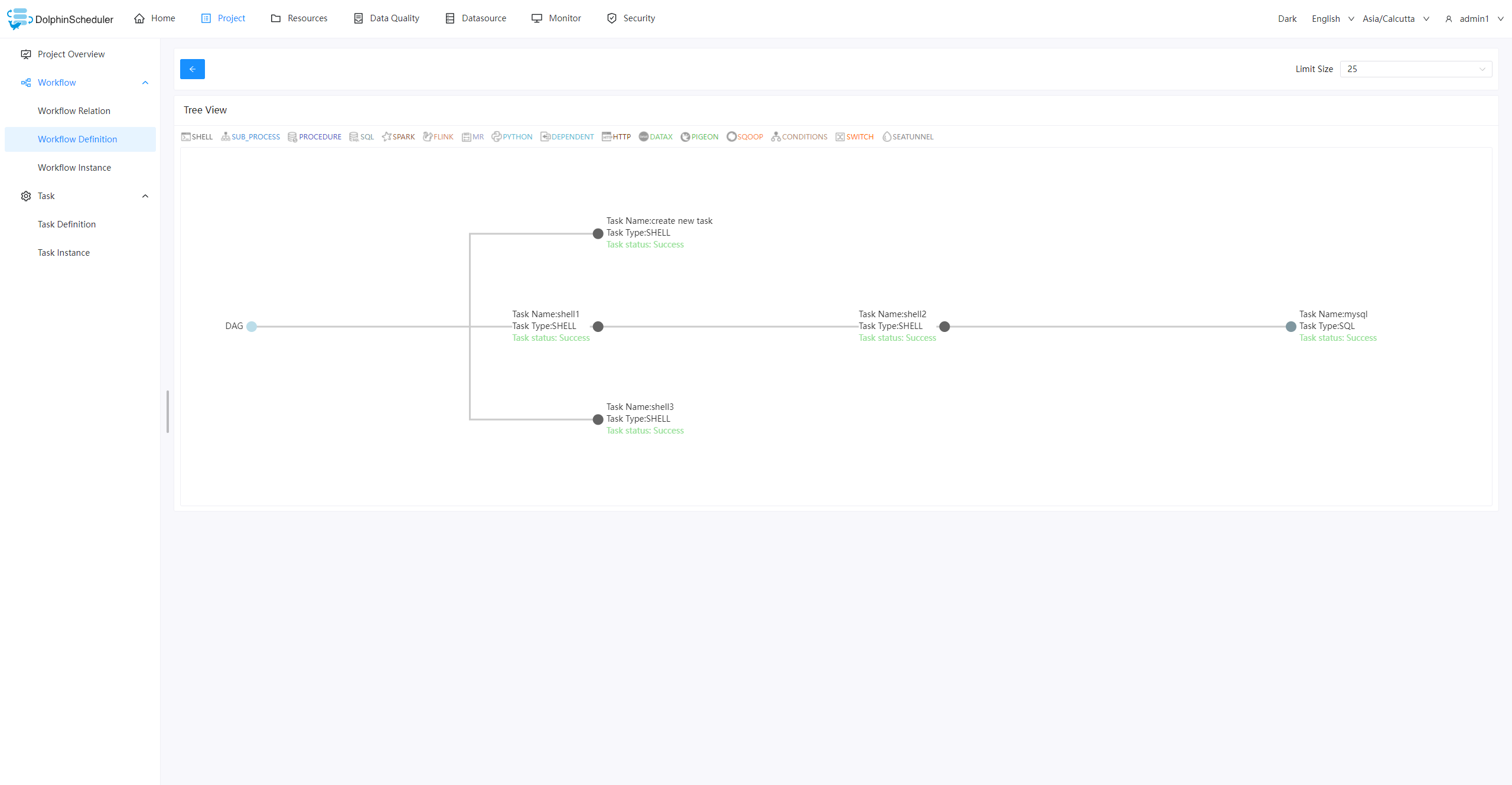
Workflow Tree View: Abstract tree structure could provide a clearer understanding of task relationships
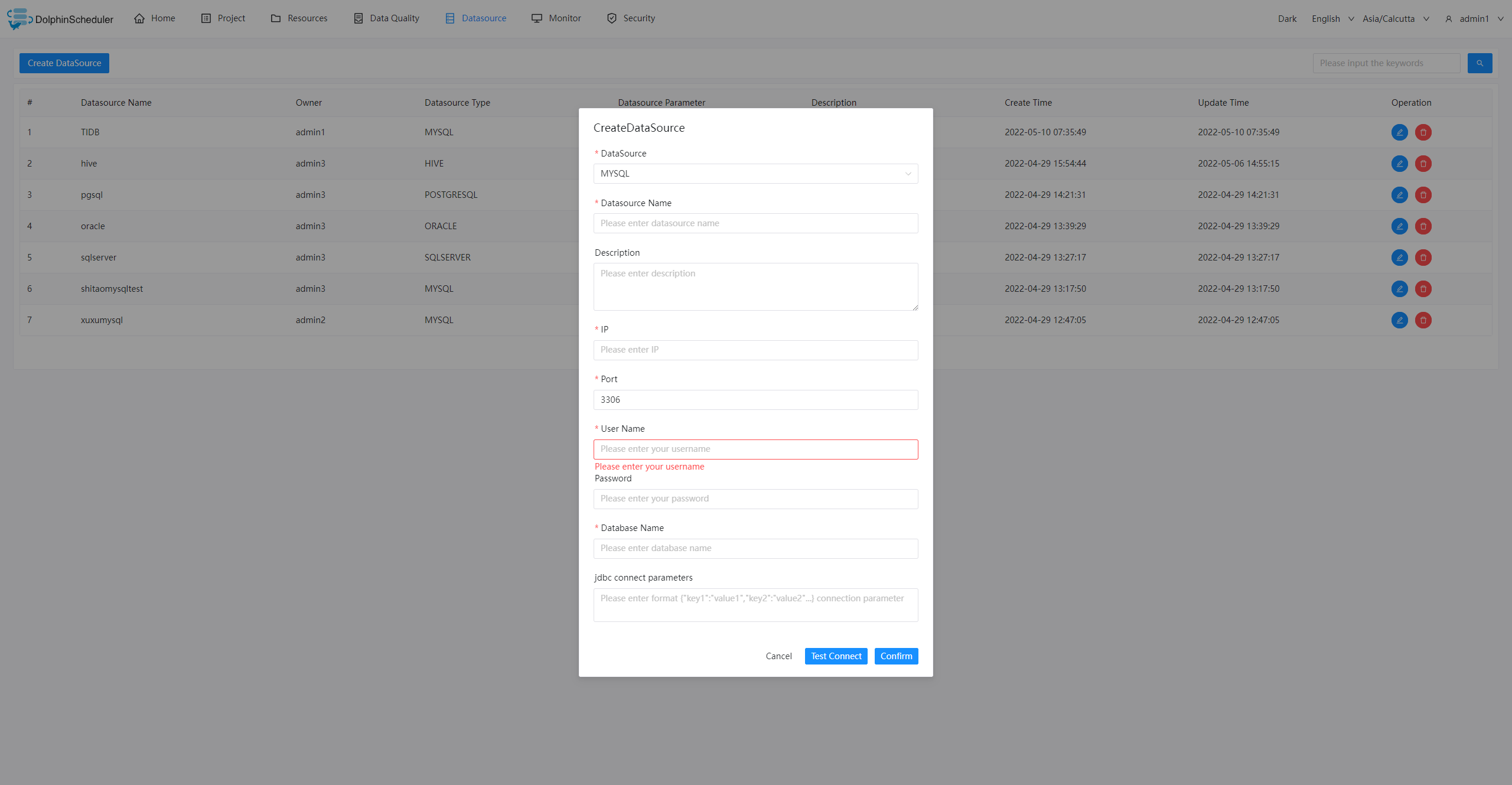
Data source: Supports multiple external data sources, provides unified data access capabilities for MySQL, PostgreSQL, Hive, Trino, etc.
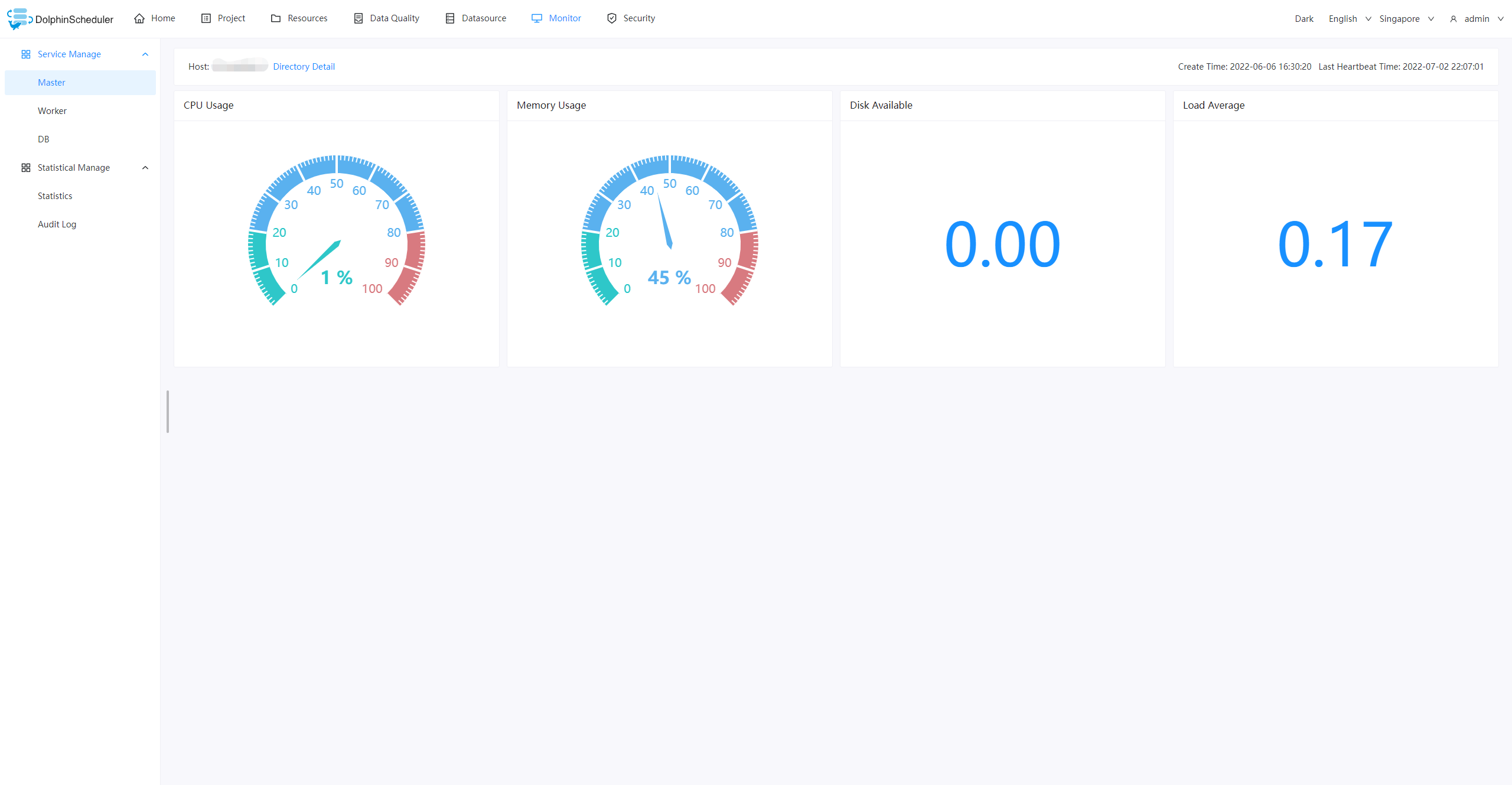
Monitor: View the status of the master, worker and database in real time, including server resource usage and load, do a quick health check without logging in to the server.
Suggestions & Bug Reports
Follow this guide to report your suggestions or bugs.
Contributing
The community welcomes contributions from everyone. Please refer to this page to find out more details: How to contribute. Check out good first issues here if you are new to DolphinScheduler.
Community
Welcome to join the Apache DolphinScheduler community by:
- Use GitHub Issues for questions, discussions, and bug reports
- Follow the DolphinScheduler Twitter and get the latest news
- Subscribe DolphinScheduler mail list, users@dolphinscheduler.apache.org for users and dev@dolphinscheduler.apache.org for developers
Landscapes


DolphinScheduler enriches the CNCF CLOUD NATIVE Landscape.
