dataframe

![]()
![]()
![]()
Kotlin DataFrame aims to reconcile Kotlin's static typing with the dynamic nature of data by utilizing both the full power of the Kotlin language and the opportunities provided by intermittent code execution in Jupyter notebooks and REPL.
- Hierarchical — represents hierarchical data structures, such as JSON or a tree of JVM objects.
- Functional — the data processing pipeline is organized in a chain of
DataFrametransformation operations. - Immutable — every operation returns a new instance of
DataFramereusing underlying storage wherever it's possible. - Readable — data transformation operations are defined in DSL close to natural language.
- Practical — provides simple solutions for common problems and the ability to perform complex tasks.
- Interoperable — convertable with Kotlin data classes and collections. This also means conversion to/from other libraries' data structures is usually quite straightforward!
- Generic — can store objects of any type, not only numbers or strings.
- Typesafe — on-the-fly generation of extension properties for type safe data access with Kotlin-style care for null safety.
- Polymorphic — type compatibility derives from column schema compatibility. You can define a function that requires a special subset of columns in a dataframe but doesn't care about other columns. In notebooks this works out-of-the-box. In ordinary projects this requires casting (for now).
Integrates with Kotlin Notebook. Inspired by krangl, Kotlin Collections and pandas
🚀 Quickstart
Looking for a fast and simple way to learn the basics?
Get started in minutes with our Quickstart Guide.
It walks you through the core features of Kotlin DataFrame with minimal setup and clear examples — perfect for getting up to speed in just a few minutes.
Documentation
Explore documentation for details.
You could find the following articles there:
- Guides and Examples
- Get started with Kotlin DataFrame
- Working with Data Schemas
- Setup compiler plugin in Gradle project
- Full list of all supported operations
- Rendering to HTML
What's new
1.0.0-rc01: Release notes
Setup
For more detailed instructions on how to get started with Kotlin DataFrame, refer to the Getting Started.
Gradle
Add dependencies in the build.gradle.kts script:
dependencies {
implementation("org.jetbrains.kotlinx:dataframe:1.0.0-rc01")
}
Make sure that you have mavenCentral() in the list of repositories:
repositories {
mavenCentral()
}
Refer to Get started with Kotlin DataFrame on Gradle for detailed setup instructions (including Groovy DSL).
- You can also check the Custom Gradle Configuration if you don't need certain formats as dependencies.
- For Android projects, see Setup Kotlin DataFrame on Android.
- See IDEA Gradle example projects and the Gradle project with the Kotlin DataFrame Compiler plugin.
Maven
Add dependencies in the pom.xml configuration file:
<dependency>
<groupId>org.jetbrains.kotlinx</groupId>
<artifactId>dataframe</artifactId>
<version>1.0.0-rc01</version>
</dependency>
Make sure that you have mavenCentral in the list of repositories:
<repositories>
<repository>
<id>mavenCentral</id>
<url>https://repo1.maven.org/maven2/</url>
</repository>
</repositories>
Refer to Get started with Kotlin DataFrame on Maven.
Kotlin Notebook
You can use Kotlin DataFrame in Kotlin Notebook, or other interactive environment with Kotlin Jupyter Kernel support, such as Datalore, and Jupyter Notebook.
You can include all the necessary dependencies and imports in the notebook using line magic:
%use dataframe
This will add the dataframe of the version bundled in the selected Kotlin Jupyter kernel.
You can use %useLatestDescriptors
to get the latest stable version without updating the Kotlin kernel:
%useLatestDescriptors
%use dataframe
Or manually specify the version:
%use dataframe(1.0.0-rc01n)
[!WARNING] Please, use
0.16.0-736Kotlin Jupyter kernel version or higher for descriptor compatibilityUse specified
1.0.0-rc01nversion in Kotlin Notebook. Due to an known issue, commondataframe:1.0.0-rc01version works incorrectly in Notebook.If you use
kandyin your notebook, add it after thedataframe:%useLatestDescriptors %use dataframe, kandy
Refer to the Setup Kotlin DataFrame in Kotlin Notebook for details.
Code example
This example of Kotlin DataFrame code with the Compiler Plugin enabled. See the full project. See also this example in Kotlin Notebook.
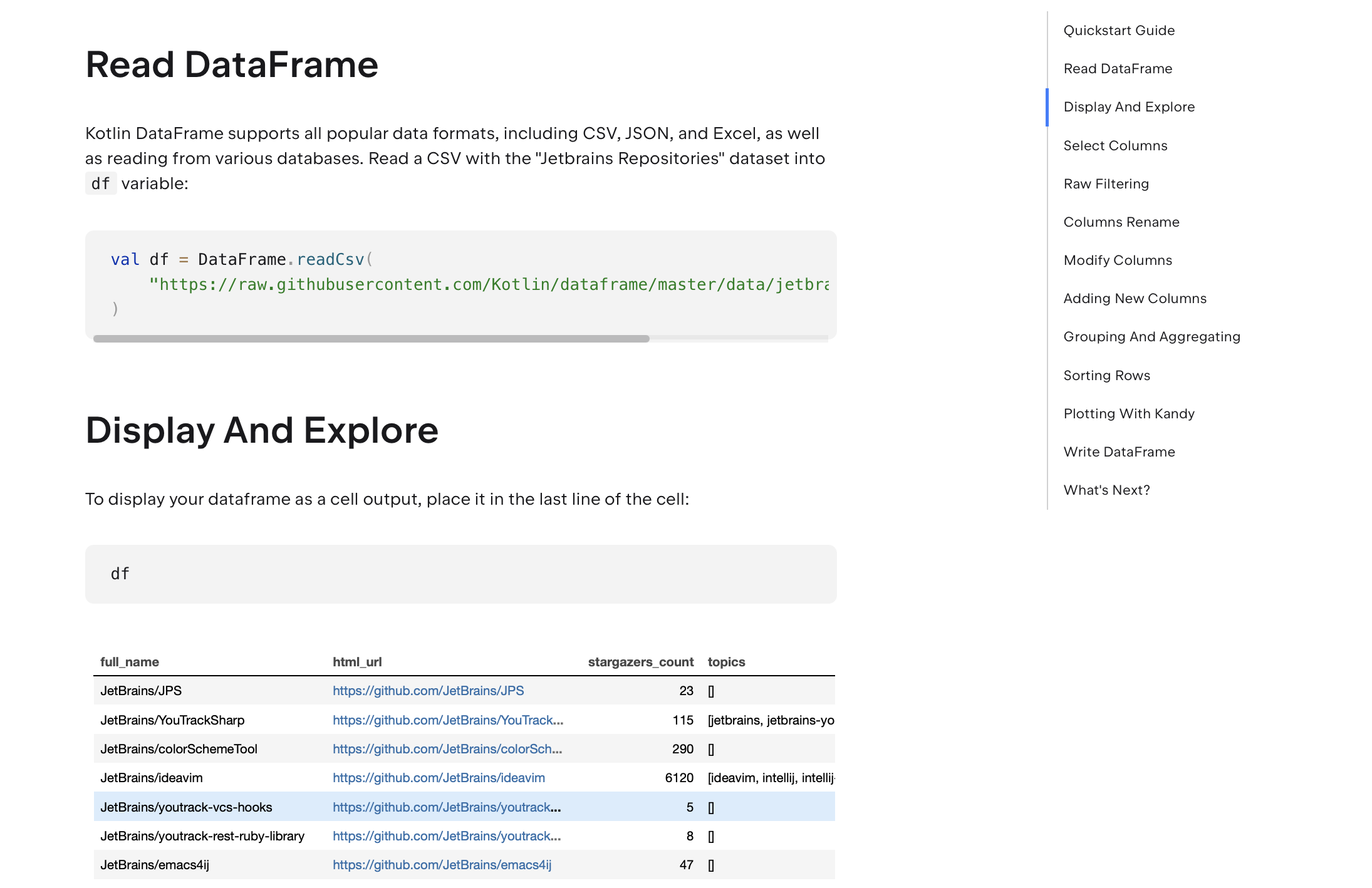
val df = DataFrame
// Read DataFrame from the CSV file.
.readCsv("https://raw.githubusercontent.com/Kotlin/dataframe/master/data/jetbrains_repositories.csv")
// And convert it to match the `Repositories` schema.
.convertTo<Repositories>()
// Update the DataFrame.
val reposUpdated = repos
// Rename columns to CamelCase.
.renameToCamelCase()
// Rename "stargazersCount" column to "stars".
.rename { stargazersCount }.into("stars")
// Filter by the number of stars:
.filter { stars > 50 }
// Convert values in the "topic" column (which were `String` initially)
// to the list of topics.
.convert { topics }.with {
val inner = it.removeSurrounding("[", "]")
if (inner.isEmpty()) emptyList() else inner.split(',').map(String::trim)
}
// Add a new column with the number of topics.
.add("topicCount") { topics.size }
// Write the updated DataFrame to a CSV file.
reposUpdated.writeCsv("jetbrains_repositories_new.csv")
Explore more examples here.
Visualizations
Kandy plotting library provides seamless visualizations for your dataframes.
Kotlin, Kotlin Jupyter, Arrow, and JDK versions
This table shows the mapping between main library component versions and minimum supported Java versions, along with other recommended versions.
| Kotlin DataFrame Version | Minimum Java Version | Kotlin Version | Kotlin Jupyter Version | Apache Arrow Version | Compiler Plugin Version | Compatible Kandy version |
|---|---|---|---|---|---|---|
| 0.10.0 | 8 | 1.8.20 | 0.11.0-358 | 11.0.0 | ||
| 0.10.1 | 8 | 1.8.20 | 0.11.0-358 | 11.0.0 | ||
| 0.11.0 | 8 | 1.8.20 | 0.11.0-358 | 11.0.0 | ||
| 0.11.1 | 8 | 1.8.20 | 0.11.0-358 | 11.0.0 | ||
| 0.12.0 | 8 | 1.9.0 | 0.11.0-358 | 11.0.0 | ||
| 0.12.1 | 8 | 1.9.0 | 0.11.0-358 | 11.0.0 | ||
| 0.13.1 | 8 | 1.9.22 | 0.12.0-139 | 15.0.0 | ||
| 0.14.1 | 8 | 2.0.20 | 0.12.0-139 | 17.0.0 | ||
| 0.15.0 | 8 | 2.0.20 | 0.12.0-139 | 18.1.0 | 0.8.0 | |
| 1.0.0-Beta2 | 8 / 11 | 2.0.20 | 0.12.0-383 | 18.1.0 | 2.2.20-dev-3524 | 0.8.1-dev-66 |
| 1.0.0-Beta3n (notebooks) | 8 / 11 | 2.2.20 | 0.15.0-587 (K1 only) | 18.3.0 | - | 0.8.1n |
| 1.0.0-Beta3 | 8 / 11 | 2.2.20 | 0.15.0-587 | 18.3.0 | 2.2.20 / IDEA 2025.2+ | 0.8.1 |
| 1.0.0-Beta4n (notebooks) | 8 / 11 | 2.2.21 | 0.16.0-736 | 18.3.0 | - | 0.8.3 |
| 1.0.0-Beta4 | 8 / 11 | 2.2.21 | 0.16.0-736 | 18.3.0 | 2.2.21 / IDEA 2025.2+ | 0.8.3 |
| 1.0.0-Beta5n (notebooks) | 8 / 11 | 2.3.20 | 0.16.0-736 | 19.0.0 | - | 0.8.4 |
| 1.0.0-Beta5 | 8 / 11 | 2.3.20 | 0.16.0-736 | 19.0.0 | 2.3.20 / IDEA 2026.1+ | 0.8.4 |
| 1.0.0-rc01n (notebooks) | 8 / 11 | 2.4.0 | 0.16.0-736 | 19.0.0 | - | 0.8.5 |
| 1.0.0-rc01 | 8 / 11 | 2.4.0 | 0.16.0-736 | 19.0.0 | 2.4.10 / IDEA 2026.1.4+ | 0.8.5 |
Code of Conduct
This project and the corresponding community are governed by the JetBrains Open Source and Community Code of Conduct. Please make sure you read it.
License
Kotlin DataFrame is licensed under the Apache 2.0 License.
