HomeworkSimilarity
项目描述:
本地作业查重系统。程序入口文件为 src/main/java/pers.hdq.ui 包中的 UIhdq.java 文件。这是一个图形化界面。
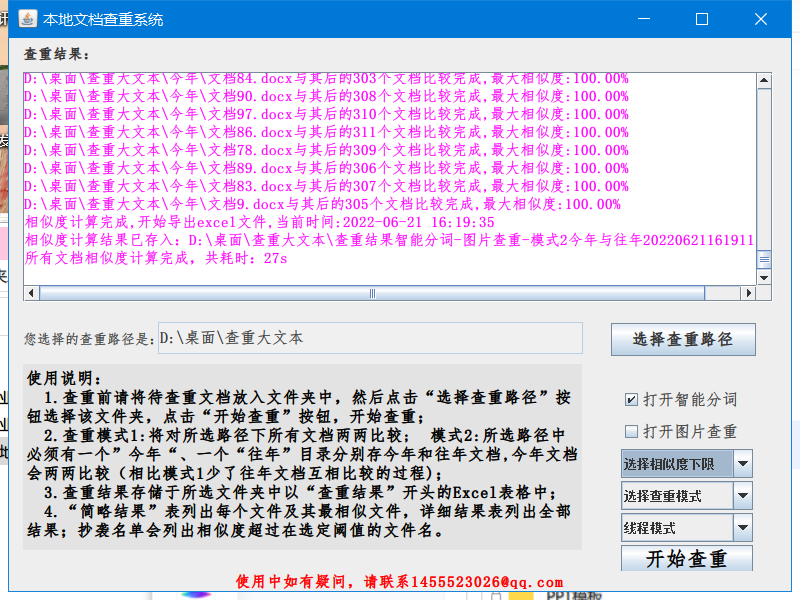
实现对本地某一目录下所有 word 文档和 txt 文档进行相似度计算。并将完整结果简略结果以及抄袭名单输出为 excel 文件。
图片相似度采用 PHash 算法,文字相似度采用 jaccard 相似度和余弦相似度结合进行计算。查重模式暂有 2 种:
①模式 1:所选目录所有文档(含子目录中的文档)两两比较;
②模式 2:要求所选目录中必须有一个"今年"文件夹存今年的文档; 一个"往年"文件夹存往年的文档; 今年文档两两比较,然后再将今年文档与往年文档分别比较;相比模式 1 减少了往年文档互相比较的过程,速度可提升 60%.
不进行图片相似度比较,多线程模式;200 个 16000 字的今年文档和 800 个 16000 字的往年文档比较;耗时 22 秒;两两比较模式下则耗时 60 秒
程序已经生成了 32 位和 64 位 exe 文件,直接解压后选择作业查重 x32 和作业查重 x64 文件夹即可运行(下载链接:链接: https://pan.baidu.com/s/1PA1x786sXzsr0J4cJI5z-A 提取码:
umfm)。
 详细图文说明,在上面的百度网盘链接中(为 2019 年初版文档),PPT 初步了解,文档 3,4 章详细介绍系统设计和实现。后续更新均在下方版本更新记录中
详细图文说明,在上面的百度网盘链接中(为 2019 年初版文档),PPT 初步了解,文档 3,4 章详细介绍系统设计和实现。后续更新均在下方版本更新记录中
release 分支为最新分支,已合并 dev1.0.3 分支;
如果对您参考价值;麻烦点亮 star 小星星鼓励一下作者吧
开发环境信息:
1.使用 maven 导入依赖;详细版本参考 pom.xml 文件;
2.基于 JDK1.8 开发
3.使用了 idea 的 lombok 插件;其他 eclipse 等用户需要自行百度安装 lombok 或者手动为 model 目录下的实体类的属性创建 get/set/方法
提示:
查询多个大文本时,请在 jvm 启动参数中调大内存限制 -Xmx4096m -Xms1024m (具体数值依据电脑配置/文档字数/文档数量等决定)
版本变更记录:
dev2.0.0 更新时间 2026-07-05
1、新增到处重复内容标记报告(html 格式),可在浏览器中查看,方便查看重复内容位置
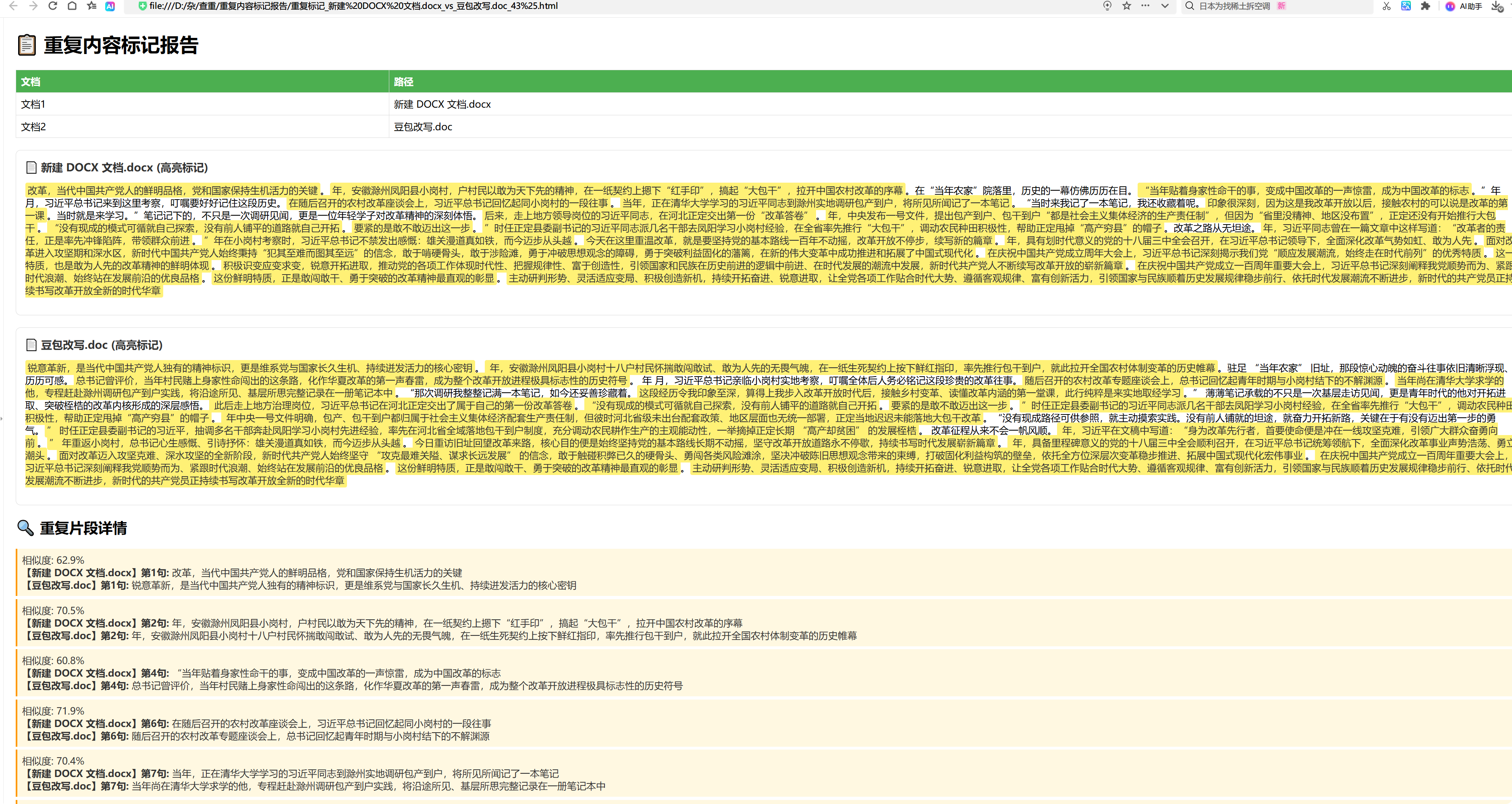
dev1.0.3 更新时间 2022-06-21
1.新增 WordUtil 工具类批量生成大文档;以便开发者测试用
2.新增多线程读取文件和多线程比较的逻辑;线程池 corePoolSize 和 maximumPoolSize 由代码读取到的 CPU 核数决定;待执行任务的队列由文本量决定
3.简化打印信息,每个文档输出一次;而不是每次比较输出一次
4.增加线程模式;用户自行选择单线程还是多线程
dev1.0.2 更新时间 2022-06-15
1.将 ik 停止词由读取文件变为 set 初始化,提高效率
2.删除冗余代码
3.新增查重模式,模式 1 即所选目录所有文档两两比较;模式 2 要求所选目录中必须有一个"今年"文件夹存今年的文档,一个"往年"文件夹存往年的文档;今年文档两两比较,然后再将今年文档与往年文档分别比较;减少往年文档互相比较的过程.
dev1.0.1 更新时间 2022-06-14
1.本次重构文件处理流程,每个文件只打开一次,效率极大提高(1000 个文档从 1 个小时提高到 1 分钟不到)
2.当详细结果超过 20 万时,详细结果不导出到 excel 中
3.当某个文档和其他文档最大相似度有多个时,简略结果只保留这个文档的 10 个最相似文档
dev1.0.0 更新时间 2022-06-13
1.本次将导出 excel 的方法换成阿里 easyExcel 库,效率极大提高(150 万行数据很快便导出完成)
