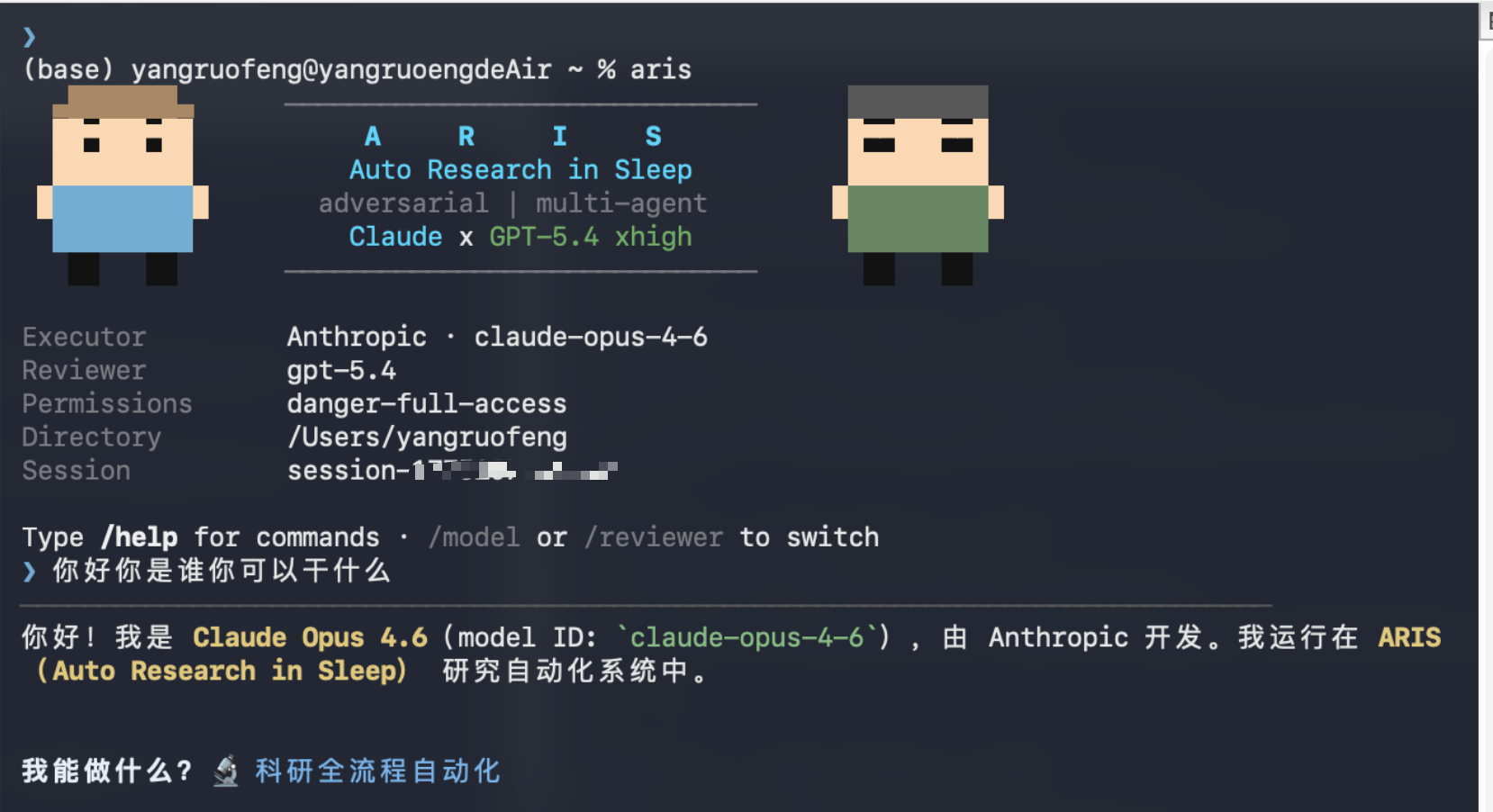
Auto-claude-code-research-in-sleep

·
·
·
·
·
·
·

💡 Use ARIS as a skill-based workflow in Claude Code / Codex CLI / Cursor / Trae / Antigravity / GitHub Copilot CLI / OpenClaw, or get the full experience with the standalone ARIS-Code CLI — enjoy any way you like!
🌱 ARIS is a methodology, not a platform. What matters is the research workflow — take it wherever you go.
🤖 AI agents: Read AGENT_GUIDE.md instead — structured for LLM consumption, not human browsing.
🛡️ ARIS audits its own output → now Anti-Autoresearch audits everyone's. It catalogs 46 integrity hack-patterns across 8 families (A–H), plus 13 zero-verdict-weight AI-style impressions and 2 advisory signals — 61 signals total — and checks a submission for them end-to-end, producing a deterministic, reviewer-ready integrity report. Self-consistency + fabrication forensics, not an AI-text detector.
The field has put up with unreliable autoresearch long enough —
Anti-Autoresearch is the read that finally catches it.
🎬 ARIS goes multimodal → ARIS-Movie-Director — hand it a rough story and get back a movie told in still frames, checked scene by scene (the reference run has 19 scenes). Long stories usually break when the model forgets earlier details or judges its own work — so ARIS keeps a research-wiki for memory and has other models check every frame.
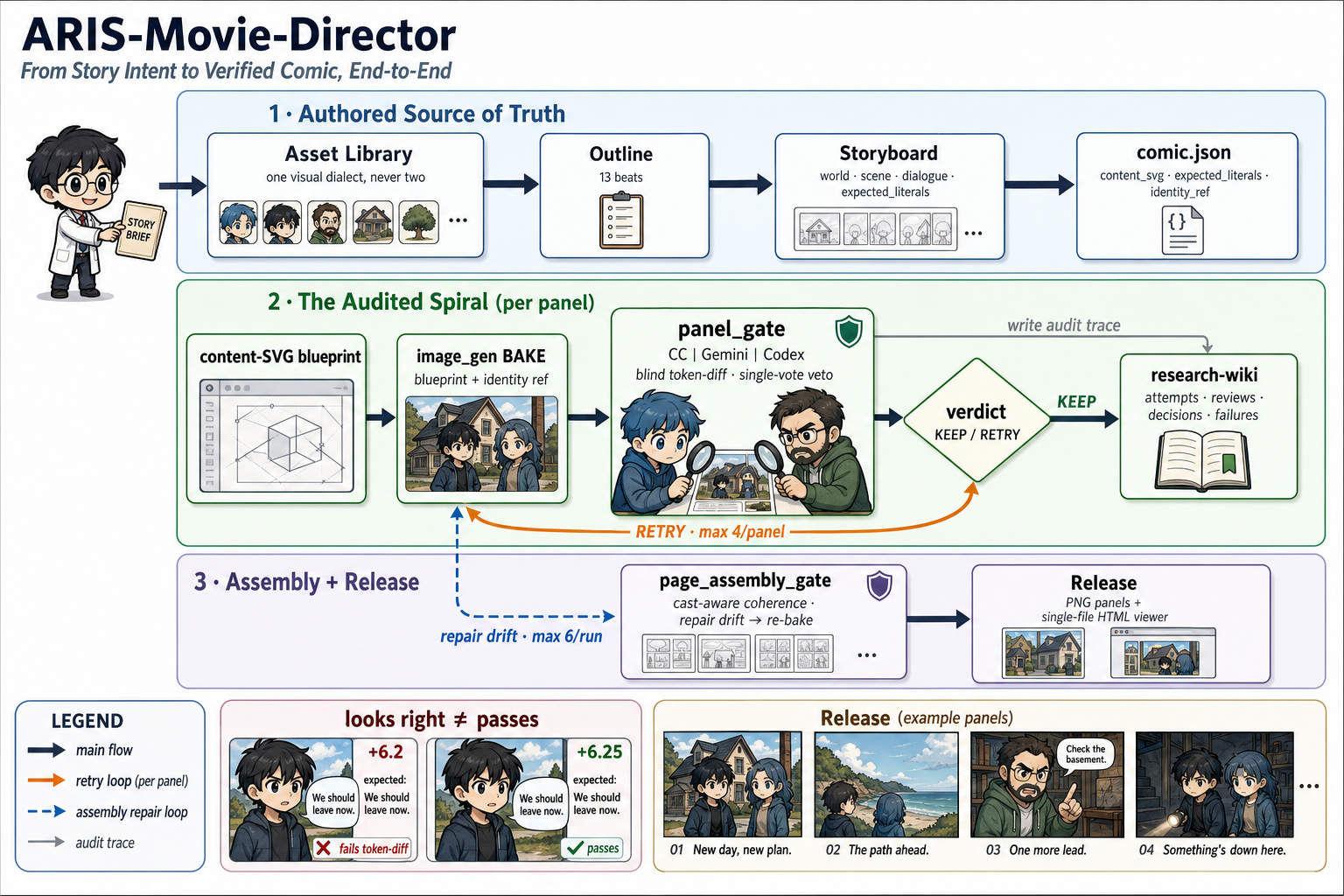
🧭 *The same loop also makes clean method / flow diagrams — the figure above was made with it. Entry points in ARIS-Movie-Director:
/movie-pipelineand/method-figure, the skill that made this figure.*
🎞️ A few frames from the reference movie — the story's own integrity beat: a run that reported +6.2 but really moved +1.4. ▶ watch all 19 scenes →
 |
 |
 |
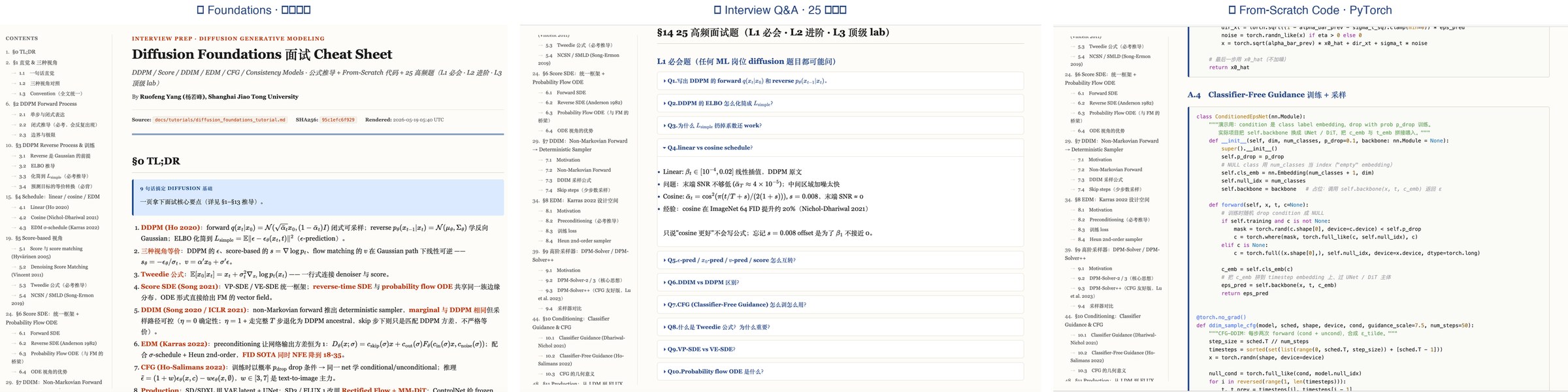
🎯 准备 2026 AI 秋招? → 🌐 ARIS-in-AI-Offer · GitHub repo · 中文 README —— 23 篇双语 ML / LLM / 多模态 / 生成式 / Agent 面试 cheat sheet,每篇 = 公式推导 + 从零 PyTorch + 25 高频面试题(L1 / L2 / L3),全部由 ARIS 的 /render-html 自动生成。希望大家秋招轻松一点 🌱
🖼️ Preview — the three-pillar cheat-sheet strip (① Foundations · ② Interview Q&A · ③ From-Scratch Code)
📝 Three long-form blogs, cross-model collaborative writing via
/render-html— Continuous DLM — a representation-perspective survey (2026 H1) · Cosmos 3 — understanding + generation in one Transformer (MoT) · Diffusion × representation × manifold learning.
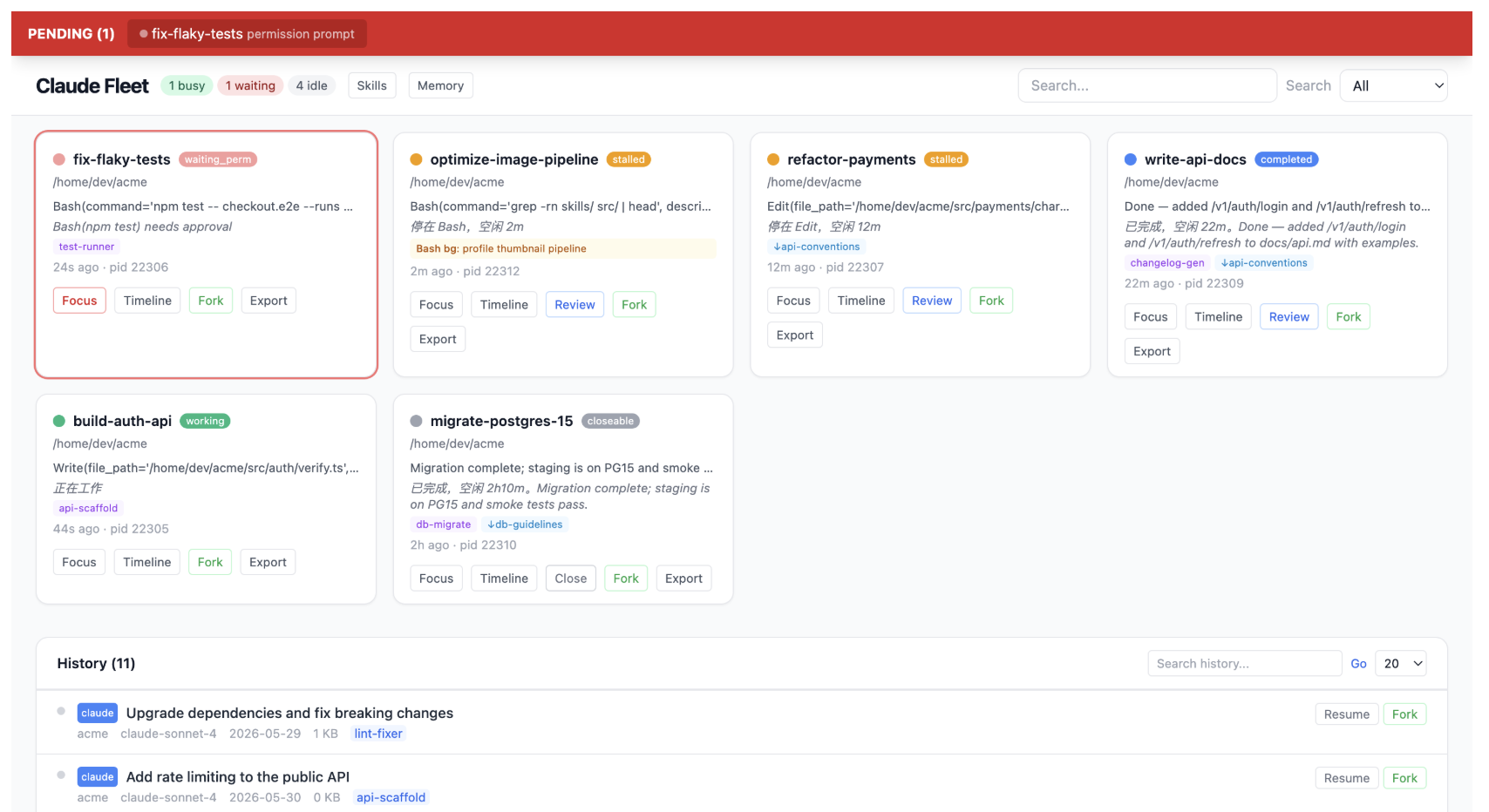
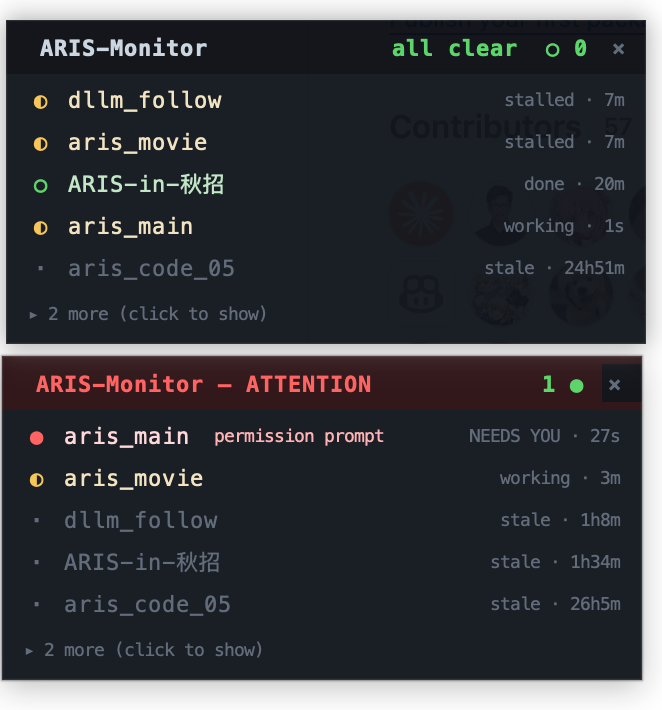
🛰 Keep an eye on your agent windows — Claude Fleet (by @tianyilt; local read-only dashboard for many parallel Claude Code / Codex windows, full-text transcript search — worth a ⭐), or the lighter built-in ARIS-Monitor (a tiny always-on-top macOS widget that lights up 🔴 when a session waits for your approval; click to jump there).
🖼️ Preview — Claude Fleet dashboard (full web) & ARIS-Monitor widget (minimal, built-in)
|
|
| Claude Fleet · 全功能网页看板 | ARIS-Monitor · 极简悬浮小窗(自带) |
Run either in seconds — ARIS-Monitor (5s) / Claude Fleet (30s)
ARIS-Monitor — built-in, no clone / no pip / no browser:
cd aris-monitor && ./run.sh
# a borderless panel floats top-right; click a row to jump to that terminal
Claude Fleet — full web dashboard:
git clone https://github.com/tianyilt/claude-fleet
cd claude-fleet && bash run.sh
# open http://127.0.0.1:7878 in your browser
🚀 Beyond 科研 → 任何 "研究":ARIS-Anything 把 ARIS 的五步 loop(plan / draft / 对抗审 / 迭代 / 持久化)推广到非学术的结构化研究——投资尽调 / 法律研究 / 市场研究 / 自驱学习 / 调查新闻 / 工程复盘等。
🔥 ARIS-Code CLI — 独立安装版 · English | ⬇️ Download ·

|
📰 ARIS-Code v0.4.22 (2026-07) — latest is the skills-resync + GPT-5.6-Sol release: the bundled skill set catches up 93 commits to this repo (79 bundled skills — incl. the new |
|
Per-release details (v0.4.5 → v0.4.22)
v0.4.22 (2026-07-12) — the skills-resync + GPT-5.6-Sol release. 📦 Bundle resync (pin 7e3ab67 → 7182624, 93 commits): 79 bundled skills (+
meta-apply, +paper-poster-html;paper-posterretired to a redirect stub), 28 tools helpers (8 new: capture_filter, evidence_check, iteration_log, provenance, run_state, threat_scan, meta_opt/trigger_eval + sample evals), 11 new shared-references docs (fan-out-pattern, acceptance-gate, external-cadence, skill-governance, compute-env-contract, resumable-runs, evidence-precheck, injection-hygiene, capture-antipatterns, output-composition, taste-calibration); sync hardening —ARIS_SYNC_EXPECT_SHAguard (aborts before touching assets if main moved; it caught a real move on first use) + exact-inventory drift tests + the vendored posterly MIT license text now ships. 🎛 GPT-5.6-Sol two-tier reviewer alignment: the CLI's system-prompt nudge now passes the skills' explicitmodel: gpt-5.6-sol+ per-call effort pins through (the v0.4.17 blanket "never pass a model" rule would have silently stripped deep audits from ultra to xhigh), carries the canonical capability-only fallback chain (effort-unsupported → same model xhigh, deep tier only; model-unknown → explicit gpt-5.5+xhigh; never degrade on transport-class errors; an explicit call-level override disables the chain), pinsapproval-policy: "never"+ explicitsandboxon every fresh codex call, and makes the HTTP fallback pre-dispatch-only with parameter stripping; the HTTP LlmReview default deliberately stays gpt-5.5 pending a real smoke; gpt-5.6 family pricing (sol $5/$30, terra $2.50/$15, luna $1/$6) verified against the official page; banner/Reviewer display//reviewerare honest about primary-vs-fallback (pure-Codex setups get status + guidance instead of a fake picker). 🐛 8 verified fixes: explicit--modelwas silently overridden by the saved executor model (model provenance now tracked end-to-end; the 4.8→4.7 availability fallback respects explicit choices;/modeland/setupre-arm it); saved models no longer leak across provider transports (blank saved models count as absent; OpenAI transport with no model source fails fast; the first-run wizard's config now actually feeds startup model resolution);--output-format jsonnever prompts (locked by a real end-to-end binary test against a mock SSE server); Windowsaris loginfixed (PKCE randomness read /dev/urandom → getrandom); Windows command probing fixed (the PowerShell tool probed itself throughsh; now where.exe); codex.cmdshims classified honestly (three-state probe; setup requires explicit confirmation before writing a config the MCP client can't spawn); nested config.json warns instead of silently parsing to all-defaults; NotebookEdit mints collision-free cell ids. 🖥 New windows-latest CI job (workspace compile gate + three targeted test groups, each guarded against silent 0-test green). Tests: api 41 / aris-cli 204 + 1 e2e / runtime 223 / tools 69 / commands 5 (+54), all green; new-code clippy delta zero. Codex MCP (gpt-5.6-sol): ultra design gate — 5 rounds, NO-GO ×4 → GO — then a 3-round implementation gate whose round 2 caught a first-run config-wiring blocker before it shipped; 4 implementation subagents, every report disk-verified.v0.4.21 (2026-06-28) — bug-fix patch: 5 new user-facing bugs from a Codex adversarial hunt (all disk-verified, distinct from v0.4.20), each cross-model reviewed at a design gate and an implementation gate (gpt-5.5 xhigh; both started NO-GO — the reviewer caught an off-by-one in the grep line-mapping and a missing stream-level test before GO). 🐛 Headline: OpenAI-compatible streaming corrupted multi-byte UTF-8 (CJK / emoji) split across network chunks into
�— each HTTP body chunk wasfrom_utf8_lossy'd independently, so a 3-byte Chinese character or 4-byte emoji straddling a chunk boundary broke on both sides (a frequent hit for Chinese users on domestic OpenAI-compatible providers — Kimi/GLM/MiniMax/DeepSeek/Qwen/Doubao — streaming Chinese text); the stream buffer is now raw bytes, decoding only complete SSE lines. A saved OpenAI/custom executor config no longer overrides a shell-setEXECUTOR_PROVIDER— the startup "shell-provided vars win" path had one ungated write that re-pointedEXECUTOR_PROVIDER=anthropic … aris …to OpenAI (wrong executor / model-not-found). An Anthropic stream truncated after content but before a terminal signal now hard-errors (premature_eof) instead of saving a half-finished answer to history as a complete turn (symmetric to the OpenAI#249guard; thestop_reason-only compat path is preserved, andARIS_ALLOW_EOF_WITHOUT_STOP=1opts a terminal-signal-less proxy back into the old behavior).grep_searchwithmultiline: truenow matches across lines in content mode (was silently empty —countmode already worked). MCP tool results carried only instructuredContent(emptycontent) are no longer dropped — the model gets the JSON structured payload. Tests (CI mode): api 32→35 / runtime 205→212 / tools 67 / aris-cli 172→181 / commands 5 (+21, incl. 2 stream-level integration tests), all green. Codex MCP (gpt-5.5 xhigh): design gate (NO-GO → GO after fixing the off-by-one) → implementation gate (NO-GO → GO after adding the stream-level integration tests); the Anthropic streaming spec (every stream ends withmessage_stop) was WebFetch-verified. Two latent-only candidates (Anthropic block-indexrouting, OpenAI multi-line SSE) remain deferred.v0.4.20 (2026-06-19) — bug-fix patch: 7 user-facing bugs surfaced by a Codex adversarial hunt, each reviewed across 3 rounds (the reviewer caught a redraw gap, a trailing-blank, a spinner tail, and a blank-line edge before GO). 🐛 Headline (#299): short REPL replies showed only "✔ Done" — the spinner draws "⠋ Thinking…" with Save/RestorePosition so streamed output overwrites it on the same line, but
finishthen cleared that whole line, erasing a short single-line reply. The REPL now finishes without clearing when the turn printed visible text (Clear(UntilNewLine)wipes only the spinner tail after the reply). Streamed multi-paragraph replies rendered glued ("para1para2") — each chunk's paragraph separator was trimmed at the stream boundary; the markdown streamer now preserves separators via a held-separator so streamed output equals a single full render (no dangling blank line). Markdown tables with CJK/fullwidth content misaligned — width now counts display cells (CJK = 2), not chars.aris "prompt"/aris setup(REPL-only before) — a configured OpenAI/custom executor got the Anthropic default sent to its endpoint; the one-shot and REPL paths now share one resolver. Esc now actually closes the completion dropdown (it was recomputed right back).glob_searchreports the total matched count when truncated (not the capped 100, which made the model think a 1000-match glob had 100 files)./model's custom menu reads the effective env the executor uses, not stale on-disk config. Tests (CI mode): api 32 / runtime 205 / tools 67 / aris-cli 172 / commands 5, all green; +7 new; real-machine verified (short reply renders + "✔ Done"; paragraphs keep their blank lines). Codex MCP (gpt-5.5 xhigh): hunt → 3 review rounds (NO-GO → NO-GO → GO). Two latent-only candidates (Anthropic block-indexrouting, OpenAI multi-line SSE) deferred to a hardening pass.v0.4.19 (2026-06-14) — honesty / guardrails patch (theme from a Codex fresh-eyes audit; no behavior change for healthy setups). 🔴 MCP protocol-version negotiation guard — the stdio handshake requested
2025-03-26but never read the version the server negotiated back (a parsed-but-dead field), so a server agreeing on a version ARIS can't speak was silently accepted and latertools/list/tools/callran on an incompatible protocol with opaque failures. ARIS now validates the negotiated version against a supported set (2025-11-25/2025-06-18/2025-03-26/2024-11-05— stdio framing is identical across these) and, on an unsupported one, terminates the child + clears the slot + surfaces a clear per-server error (aris doctorshows it) — the "terminate when versions can't be agreed" behavior the MCP lifecycle spec requires. The request stays2025-03-26(proven againstcodex mcp-server), so healthy servers are unaffected — verified end-to-end: the real Codex MCP server still spawns + initializes + advertises its tools under the guard. 🧹 Papercuts: the OpenAI-family subagent fail-loud message dropped its stale "lands in v0.4.18" marker (now version-agnostic + actionable, still credential-free); OpenAI upstream error bodies are now truncated (500 chars) + credential-redacted (sk-…keys andBearer …tokens, via a substring scanner that catches the compact-JSON shape{"api_key":"sk-…"}a misconfigured proxy can reflect back) instead of splatted verbatim; the system-prompt hook-events summary now counts only the hooks the runtime actually executes (acommandhook with acommandstring), matching the parser. Tests (CI mode): api 32 / runtime 204 / tools 67 / aris-cli 167 / commands 5, all green; live smoke confirms the real Codex MCP server still initializes under the guard. Reviewed by Codex MCP (gpt-5.5 xhigh): design GO → impl NO-GO (compact-secret miss + command-string strictness) → GO after fixes.v0.4.18 (2026-06-14) — default model → Claude Opus 4.8, with corrected pricing and a safety net. The bump moves
DEFAULT_MODEL, theopusalias, the model picker,aris setup, and the subagent default toclaude-opus-4-8— with an availability fallback: if the account lacks 4.8 (the API returns404 not_found_error), ARIS auto-falls-back toclaude-opus-4-7for the session, rebuilds the system-prompt model identity so it stays coherent (the model is never told it's 4.8 while served 4.7), warns once, and retries — for the main session (text + JSON) and subagents. It fires only on that precise 404 (never 400/rate-limit/auth), latches against loops, and the text path rebuilds from a pre-turn snapshot so a retry never double-appends the user message; accounts with 4.8 are byte-identical to a plain bump. 💰 Pricing corrected (verified against Anthropic's published schedule; had been a 3–5× over-estimate): current Opus 4.5–4.8 =$5/$25(deprecated Opus 4/4.1 keep$15/$75, split by word-boundary so a futureopus-4-10isn't mis-tiered); Sonnet 4.x =$3/$15(decoupled from the generic unknown-model fallback, which stays$15/$75); Haiku was already correct. 🧹 Backlog:aris setupoption 10 pins the Codex MCP reviewer tomodel_reasoning_effort="xhigh"(deterministic for new setups, independent of~/.codex/config.toml; idempotent merge never clobbers an existing entry); a startup +aris doctormisconfig hint (#259) for a silently-ignored/misplaced config (malformed JSON, or a stray~/.aris/config.yaml— stderr-only soSessionStart/SessionEnd/… — deferred to a separate issue). Tests (CI mode): api 32 / runtime 202 / tools 67 / aris-cli 166 / commands 5, all green; a live one-shot smoke returnsmodel=claude-opus-4-8end-to-end. Reviewed by Codex MCP (gpt-5.5 xhigh) across the design + both implementation batches (design REWORK→GO, impl NO-GO→GO, batch-2 GO).v0.4.17 (2026-06-13) — the MCP release. Before v0.4.17,
mcpServersinsettings.jsonparsed, showed inaris doctor, and did nothing; now ARIS spawns each configured stdio server, runs the MCP handshake, discovers tools, and advertises them asmcp__<server>__<tool>on both provider paths (Anthropic + OpenAI-family), with end-to-end dispatch, soft per-server degradation, and an approval gate for untrusted MCP tools (external processes the sandbox can't cover;--allowedToolsnow acceptsmcp__names). 🆕 zero-API-key cross-model reviewer:aris setup→ option 10 (Codex MCP, ChatGPT subscription, no API key) writes an idempotentmcpServers.codexentry into the settings file the runtime actually reads (atomic write + backup, explicit consent beforetrust: true), with an optional API reviewer as fallback (ARIS_REVIEWER_PROVIDER=codex-mcp+ARIS_REVIEWER_FALLBACK_PROVIDER);/setupin-REPL rebuilds the system prompt + runtime so reviewer changes take effect without quitting. 🔴 Protocol fix the fakes couldn't catch: real-machine e2e againstcodex mcp-serverexposed that our stdio transport spoke LSP-styleContent-Length:framing while the MCP spec (and codex) use newline-delimited JSON-RPC — every fake-server test passed because the fakes spoke the same wrong dialect; writes are now NDJSON, reads auto-detect both, and the spec-mandatednotifications/initializedis sent afterinitialize(a select-based round-trip also closes the #286 large-request deadlock). Hooks: object-style Claude Code hooks preservematcher/timeout/async(anchored-regex matcher filtering; per-hook timeout, default 30 s kill = warning not deny). Long tail:ARIS_DISABLE_KEYCHAINgate, Anthropicstop_reasonclean-EOF symmetry (CL2), OpenAI tool-callindex-missing merge-by-id (OE6), slash commands enter history. Real-machine push-gate hardening (the zero-key reviewer's first run): codexcodex/eventnotification spam silenced by default (gated behindARIS_MCP_STDERR=inherit), the system prompt now tells the model not to pass amodelparameter to Codex (account default = gpt-5.5 + xhigh; arbitrary names are rejected by a ChatGPT account), and a Codex-MCP-primary-with-no-fallbackLlmReviewcall returns a clear "usemcp__codex__codex" message instead of a misleadingOPENAI_API_KEY/gpt-5.5error. Built with the v0.4.16 zero-regression methodology (24 new characterization tests; every deliberate flip annotated in-place). Tests (CI mode): runtime 199 / aris-cli 165 / tools 67 / api 30 / commands 5, all green. Reviewed phase-by-phase by Codex MCP (gpt-5.5 xhigh) across 17 rounds (7 NO-GOs all resolved). Subagent MCP routing (P8) + MCPprotocolVersionbump + hookasyncexecution deferred to v0.4.18.v0.4.16 (2026-05-30) — REPL UX + provider hardening, shipped under a zero-regression discipline: 64 characterization ("golden") tests locked the current provider-routing / pricing / reviewer / subagent / REPL behavior first, then stayed green through every change. Closes #274: command history now persists to
~/.config/aris/history(0600) and reloads on startup, with anARIS_NO_HISTORYkill-switch and a disk-only secret-skip (credential-looking lines stay in in-session history but never touch disk); bash-style Ctrl+R reverse incremental search (CJK display-width-aware single-line render; no existing key binding changed; no new dependency). Security: an OpenAI-family main session (Kimi / GLM / MiniMax / …) spawning a subagent previously silently billed the user's Anthropic OAuth/Keychain credential — it now fails loud with a clear, credential-free error; full OpenAI-family subagent routing is a cross-crate change deferred to v0.4.17. Groundwork (no behavior change): the 3 byte-identical word-boundary matchers consolidate into one canonicalruntime::word_match; new pureProviderFamilyclassifier (unwired). Tests (CI mode): runtime 164 / aris-cli 128 / tools 49 / commands 5, all green. Codex MCP (gpt-5.5 xhigh) reviewed each phase + a final integration pass.v0.4.15 (2026-05-29) — OpenAI-compatible streaming robustness hotfix. Closes #249: MiniMax (and other OpenAI-compatible providers / proxies) were effectively unusable because the clean-EOF completion check treated the
data: [DONE]SSE sentinel as the only authoritative signal. A non-emptychoices[].finish_reasonis the Chat Completions spec's terminal-chunk marker;[DONE]is a transport convention some compatible providers never emit (MiniMax sendsfinish_reason: "stop"then closes without[DONE]). The clean-EOF decision is now a pure, unit-testedstream_eof_action(...)that completes on EITHER[DONE]OR a non-emptyfinish_reason; reads are NOT stopped early at finish_reason (a trailinginclude_usageusage-only chunk is still consumed), genuine truncation still hard-errors, and a pre-output proxy abort still restarts. Coupled fixes: OE7 reads finish_reason before thedeltaguard (delta-less terminal choice); OE2 flushes pending tool calls on any non-empty finish_reason; OE4 surfaces a mid-stream error envelope as a hard error instead of silently dropping it; OE3 toleratesdata:{...}without the space after the colon. +5 unit tests (77→82) extract the previously-untested SSE completion logic into pure helpers. Anthropic SSE path untouched. Codex MCP (gpt-5.5 xhigh) 3 rounds (GO-WITH-NITS → GO-WITH-NITS → GO).v0.4.14 (2026-05-25) — Security-hygiene release closing the top items from the v0.4.13 codex audit (gpt-5.5 xhigh, 6/10 NEEDS-REWORK verdict). 🔴 S9 (P0) system-prompt config redaction — before v0.4.14,
render_config_section()dumped the mergedsettings.jsonverbatim into the system prompt sent to the LLM provider, leakingenv,mcpServers.<name>.headers.AuthorizationBearer tokens, hook command env, signed-URL query params, andapiKeyfields. New renderer whitelists top-level fields (model/permissionMode/theme/outputStyle/permissions/sandboxwith recursive redaction inside), redacts sensitive keys (apikey/token/secret/password/authorization/headers/env/_KEY/_SECRET/_TOKEN), replaces MCPcommandwith<configured>placeholder, reduces MCPurlto strict<scheme://host[:port]>origin (scheme allow-listhttp/https/ws/wss, ASCII host, digit-only port, IPv6 brackets), and drops hook command strings entirely. Regression test exercises 9 distinct leak surfaces; URL parser has its own targeted test for 7 smuggling attempts including port-position secret injection (codex round-3 catch). 🟡 P9 (P1): DeepSeekaris --helpnow points ataris setupoption 7 instead of an env-var path the resolver never honored. 🟡 M1/M2 (P1) doc:aris doctor+ README/README_CN gain experimental warning whenevermcpServers.len() > 0(full MCP tool dispatch lands v0.4.16). 🟢 C11 (P2) stream idle timeout — both AnthropicMessageStreamand the OpenAI SSE loop wrapresponse.chunk().awaitintokio::time::timeout(envARIS_STREAM_IDLE_TIMEOUT_SECS, default 120, clamp[10, 1800], 0/negative disables); closes the "aris hangs forever with no output" symptom when an upstream HTTPS proxy holds a connection without keepalives. Bundle: 77 skills (+1/wiki-enrichvia late same-day sync to main7e3ab67which also picks up upstreamcheck_ready.shawk + grep-c null-match fix), 54 helpers. Codex MCP 6 rounds (NO-GO + 4 → GO-WITH-NITS + 3 → NO-GO + port smuggling → GO → release metadata GO → sync GO).v0.4.13 (2026-05-25) — Residue-cleanup release closing every codex audit P1 carried since v0.4.10–v0.4.12, plus the long-tail regression tests. 🟡 v0.4.10 P1.D per-server MCP timeout —
mcpServers.<name>.requestTimeoutSecsoverride >MCP_REQUEST_TIMEOUT_SECSenv > 300s default (clamped 1..=1800), so one Codex MCP agent can run 5 min while filesystem MCP errors in 5 s. 🟡 v0.4.10 known limitation closed —McpStdioProcess::request()skips JSON-RPC notifications (id absent/null) and keeps reading until the correlated response. 🟢 meta_opt hook deploy viaaris init—tools/meta_opt/{log_event,check_ready}.shbundle into the binary;aris initwrites ARIS-namespacedaris-meta-opt-log-event.sh/aris-meta-opt-check-ready.shto~/.claude/hooks/(codex round-1 #1: never clobbers user hooks); settings.json merge idempotent, backups hard-fail, final rewrite atomic via tempfile + rename. 🧪 9 v0.4.12 targeted regression tests for sandbox.strictMode (3) + parse strictMode + provider_match pricing + has_word o-series + stream_options 400 + meaningful-content classification + premature-EOF retry truth table (codex round-1 #3 —should_retry_on_premature_eof()extracted to pure fn, 7-row test). Bundle: 76 skills, 54 helpers (+2 meta_opt scripts vs v0.4.12). Codex 3 rounds (NO-GO + 3 → NO-GO + metadata → GO).v0.4.12 (2026-05-22) — Bug-fix + small-feature release. #238
sandbox.strictModeopt-in config key; when set,SandboxConfig::resolve_request()ignores all five LLM-supplied overrides (dangerouslyDisableSandbox,namespaceRestrictions,isolateNetwork,filesystemMode,allowedMounts) — closes the gap where a tool call could silently bypass user sandbox policy.aris doctoradds a "Sandbox:" row; bash tool schema documents the strictMode semantics. #232auto-review-loop-llmupdated from legacydeepseek-chat/deepseek-reasoner(deprecate 2026-07-24; reasoner rejectstool_choice) todeepseek-v4-flash/deepseek-v4-pro. v0.4.10 audit P1 follow-ups: P1.A Anthropic stream retry gates onhas_emitted_meaningful_content(a stream that only sentMessageStartbefore EOF is retry-eligible); P1.Bsupports_reasoning_effort+ reviewer mirror use word-boundary match soopenai/o3-mini/proxy:o4route correctly; P1.Cstream_options.include_usage:trueproxy fallback retries once without on real 400 unknown-field errors; P2 pricing match precision viaprovider_match()soqwen3.6-plus/kimi-k2.5route correctly whilemy-kimi-clonedoes not. Skills sync (76 skills, 52 helpers):/interview-cheatsheet+/render-htmlnewly bundled;build.rsALLOWED_EXTSgainshtmlfor render-html templates;EXCLUDED_SKILL_PREFIXES→starts_with("skills-codex"). CI fetch-depth: 0 + origin/main fetch so drift-test ancestor check runs. Cross-reviewed by Codex MCP (gpt-5.5 xhigh) over 4 rounds.v0.4.11 (2026-05-18) — Skills bundle refresh + sync infrastructure. The embedded skills set in the v0.4.10 binary had fallen behind main (~6 of 56 main
skills/commits had been cherry-picked); v0.4.11 syncs the full set and ships sync infrastructure so the gap can't silently reopen. Bundle: 65→74 user-facing skills, 34→49 helper resources. 10 new skills bundled:/citation-audit(fourth-layer bibliography audit),/experiment-queue(SSH multi-seed job queue with OOM retry),/kill-argument(two-thread adversarial review for theory papers),/resubmit-pipeline(W5: text-only port to a new venue),/paper-talk(end-to-end conference talk pipeline),/slides-polish(per-page Codex layout review),/overleaf-sync(two-way Overleaf Git-bridge),/gemini-search+/openalex(broader literature sources),/qzcli(Qizhi GPU jobs). 46 existing SKILL.md refreshed — most critically the canonical resolver chain rollout (closes real user incident where/research-wikiwas empty for a week from hardcodedtools/research_wiki.py), submission assurance gate + external verifier (/paper-writingPhase 6 now functions). tools/ goes 9→18: 9 baseline helpers refreshed (research_wiki.py315→767 lines with canonicalingest_paperAPI), 9 new helpers (extract_paper_style.py,figure_renderer.py,paper_illustration_image2.py,overleaf_{setup,audit}.sh,verify_wiki_coverage.sh,watchdog.py,experiment_queue/{build_manifest,queue_manager}.py). Newtools/sync_main_skills.shautomates main → bundle rsync with symlink pre-flight + codex-mirror prune +SKILLS_SOURCE_COMMITpinning. 3 new CI drift tests incrates/runtime/src/cache.rscover all 4 resolver layer patterns. Gemini MCP calls in/research-litand/gemini-searchnow passmodel: 'auto-gemini-3'(avoids silent downgrade to 2.5-pro on OAuth-personal capacity exhaustion). CLI runtime unchanged — codex-audit P1 follow-ups remain on v0.4.12 backlog. Cross-reviewed by Codex MCP (gpt-5.5 xhigh) across 5 rounds (REQUEST CHANGES → APPROVE WITH NITS → NO-GO → GO → final GO).v0.4.10 (2026-05-17) — Stream + MCP reliability + multi-provider pricing. C6 whole-stream restart in Anthropic
MessageStream+ OpenAI SSE loop on chunk decode failure / premature EOF (ARIS_STREAM_RETRY, default 2, clamp 0..=5, fires only when nothing emitted yet — closes #228-style "error decoding response body" loop). M3 MCP stdio gains 300s defaulttokio::time::timeoutover send+read (overrideMCP_REQUEST_TIMEOUT_SECS, clamp 1..=1800);response.id ↔ request.idcorrelation;ensure_server_ready()try_wait()dead-process respawn;kill().awaiton all failure paths so the next call starts clean (closes #151 / #172 "Calling codex..." stalls). C8/P4 OpenAI streaming requests now sendstream_options.include_usage:true+ parsecached_tokens; Anthropic streaming mergesMessageStart.usage(input/cache) withMessageDelta.usage(output). C9 multi-provider pricing registry (15+ models, OpenAI cache_read = input × 0.1 corrects 5× generic overstatement, DeepSeek cache_hit/cache_miss tiers,has_word()boundary matcher forprovider/<model>slugs). 9 dead-code warnings cleared;aris setuphelp text synced with actual behaviour.v0.4.9 (2026-05-17) — Closes Codex v0.4.7 audit residuals (L1 TLS double-stack, L3 reasoning_cache compaction misalign, L4 reasoning replay unbounded). 2 new skills bundled (
/figure-spec+/paper-illustration-image2withscripts/subdirs, new Layer 0b =$ARIS_CACHE_DIR/skills/<name>/scripts/);research_wiki.pypromoted to sharedtools/(9+ callers); 5 more SKILL.md migrated to fallback chain.v0.4.8 (2026-05-17) — Skill helper subsystem rewrite. Bundled helpers extract to
~/.config/aris/cache/<version>/at startup; every Skill invocation surfaceshelperReportJSON + 4-layer resolver preamble;/skills exportcopies helpers; newintegration-contract.mdwith 6 failure policies; 8 shared helpers (arxiv/deepxiv/exa/S2/openalex/save_trace/verify_papers/verify_paper_audits) bundled;/research-lit+/deepxivmigrated. Plus 4 bug fixes: gpt-5.5+tools 400 on OpenAI; Custom reviewer reset; missingsignaturefield (#228);--versionBuild date hardcoded.v0.4.7 (2026-05-16) — DashScope Coding Plan 405 fixed (#159) via
native-tlsswitch (#225);reasoning_contentreplay for all reasoning models (OpenAI o1/o3/o4 / DeepSeek-R1 etc.), not just Kimi (#226); 600+ lines dead code cleanup +rustylinedep removed + "Claw Code" → "ARIS-Code" rebrand.v0.4.6 (2026-05-14) — 🚨 Two long-standing silent bugs fixed:
PermissionMode::Promptsilently allowed every tool (derived-Ordbug); system prompt hardcodedcurrent_date = "2026-03-31"made models reject post-cutoff data as future/prompt-injection. Plus Custom OpenAI-compatible provider (/setupoption 11) with dynamic/modelsdiscovery (@Anduin9527 #221 + #222).v0.4.5 (2026-05-13) — First-class reasoning-model support: thinking content blocks end-to-end (fixes #161) +
reasoning_effort='xhigh'for GPT-5.5 / o1 / o3 / o4 / DeepSeek-thinking. DeepSeek V4 Pro + Xiaomi MiMo + Qwen 3.6 + Doubao in/setup(options 7-10). Object-style hooks parser. Default model bumped to Claude Opus 4.7 + GPT-5.5. REPL input hardening (multi-line wrap / Cmd+V paste / CJK boundary). GitHub Actions CI. Credits: @GO-player-hhy (#186), @Jxy-yxJ (#171), @GetIT-Sunday (#216 partial).Older versions
v0.4.4 (2026-04-20) — Setup UX + reviewer routing fixes (resolves #158, #162) |
/setupno longer forces Bearer for Anthropic + custom URL | Provider-aware proxy URL hints | Stale state no longer leaks across provider switches | LlmReview smart fallbackv0.4.3 (2026-04-17) — Third-party Anthropic-compat proxy support (Bedrock etc.) | Skip beta flags that proxies reject | Propagate custom base URL for
anthropicprovider | Credit @screw-44v0.4.2 (2026-04-17) — Auto-compaction corruption fix | Compaction summary preserved on OpenAI-compat executors | Shell-provided API keys no longer erased on launch
v0.4.1 (2026-04-15) — Plan mode (
/plan) | Cooperative Ctrl+C interrupt | Auto-retry (429/5xx/network) | Research Wiki 📚 (persistent knowledge base) | Self-Evolution 🧬 (/meta-optimize) | Local models (LM Studio/Ollama) | 62 skills syncedv0.3.11 (2026-04-13) — Reviewer Anthropic-compatible mode (Claude via proxy)
v0.3.9 (2026-04-11) — Proxy/custom base URL (CCSwitch) | Local models (LM Studio/Ollama) | Windows (experimental)
v0.3.5 (2026-04-08) — Research Wiki (persistent papers/ideas/experiments/claims + relationship graph) | Meta-Optimize self-evolution (analyze logs → propose SKILL.md patches)
v0.3.0 (2026-04-03) — Multi-file memory index | Rich task system (TodoWrite) |
/plan| Security hardeningv0.2.2 (2026-04-03) —
/planstep-by-step planning |/taskspersistent trackingv0.2.1 (2026-04-03) — Persistent Memory | Kimi K2.5 multi-turn fix | CJK cursor fix
v0.2.0 (2026-04-02) — Open source | Kimi + MiniMax + GLM support | Smart LlmReview routing | CI/CD
v0.1.0 (2026-04-02) — Initial release | Multi-executor & reviewer | 42 bundled skills
![]()

中文版 README | English
🌙 Let Claude Code do research while you sleep. Wake up to find your paper scored, weaknesses identified, experiments run, and narrative rewritten — autonomously.
🪶 Radically lightweight — no infrastructure, zero lock-in. The entire skill layer is plain Markdown files. No framework to learn, no database to maintain, no Docker to configure, no daemon to babysit. Every skill is a single
SKILL.mdreadable by any LLM — swap Claude Code for Codex CLI, OpenClaw, Cursor, Trae, Antigravity, Copilot CLI, Windsurf, or your own agent and the workflows still work. Fork it, rewrite it, adapt it to your stack.
Custom Claude Code skills for autonomous ML research workflows. These skills orchestrate cross-model collaboration — Claude Code drives the research while an external LLM (via Codex MCP) acts as a critical reviewer. 🔀 Also supports alternative model combinations (Kimi, LongCat, DeepSeek, etc.) — no Claude or OpenAI API required. For example, MiniMax-M3 + GLM-5 or GLM-5 + MiniMax-M3. 🤖 Codex CLI native — full skill set also available for OpenAI Codex. 🖱️ Cursor — works in Cursor too. 🖥️ Trae — ByteDance AI IDE. 🚀 Antigravity — Google's agent-first IDE. 🐙 Copilot CLI — GitHub's terminal agent (native SKILL.md + MCP). 🆓 Free tier via ModelScope — zero cost, zero lock-in.
💭 Why not self-play with a single model? Using Claude Code subagents or agent teams for both execution and review is technically possible, but tends to fall into local minima — the same model reviewing its own patterns creates blind spots.
Think of it like adversarial vs. stochastic bandits: a single model self-reviewing is the stochastic case (predictable reward noise), while cross-model review is adversarial (the reviewer actively probes weaknesses the executor didn't anticipate) — and adversarial bandits are fundamentally harder to game.
💭 Why two models, not more? Two is the minimum needed to break self-play blind spots, and 2-player games converge to Nash equilibrium far more efficiently than n-player ones. Adding more reviewers increases API cost and coordination overhead with diminishing returns — the biggest gain is going from 1→2, not 2→4.
Claude Code's strength is fast, fluid execution; Codex (GPT-5.6-Sol xhigh) is slower but more deliberate and rigorous in critique. These complementary styles — speed × rigor — produce better outcomes than either model talking to itself.
🧿 Want the strongest possible reviewer? Add
— reviewer: oracle-proto any skill to route reviews through GPT-5.5 Pro via Oracle MCP. Pro-level reasoning for proof verification, experiment auditing, and final stress tests. Works with API key or free browser mode. Setup →
Contents
- More Than Just a Prompt
- What's New · changelog
- Quick Start · install + first run
- Features
- Score Progression (Real Run)
- Community Showcase — Papers Built with ARIS
- Awesome Community Skills & Extensions
- Workflows · 13 named pipelines (W1 / W1.5 / W2 / W3 / W4 / W5 / W6 / Wiki / WM + Effort / Assurance / Oracle)
- Setup · prerequisites / install / update / usage / GPU server config
- Customization · per-skill config knobs
- Alternative Model Combinations · GLM / MiniMax / Kimi / etc.
- Community
- Citation
- Star History
- Acknowledgements
- License
1. 🎯 More Than Just a Prompt
These are full pipelines — you can also use each workflow independently. Already have an idea? Skip to Workflow 1.5. Have results? Jump to Workflow 3. Got reviews? Jump to Workflow 4. Want persistent memory? Enable Research Wiki. See Quick Start for all commands and Workflows for the full breakdown.
Basic mode — give ARIS a research direction, it handles everything:
/research-pipeline "factorized gap in discrete diffusion LMs"
🔥 Targeted mode — got a paper you want to improve? Give ARIS the paper + the code:
/research-pipeline "improve method X" — ref paper: https://arxiv.org/abs/2406.04329, base repo: https://github.com/org/project
ARIS reads the paper → finds its weaknesses → clones the codebase → generates ideas that specifically fix those weaknesses with that code → runs experiments → writes your paper. Like telling a research assistant: "read this paper, use this repo, find what's missing, and fix it."
Mix and match:
ref paperonly = "what can be improved?",base repoonly = "what can I build with this code?", both = "improve this paper using this code."
🔥 Rebuttal mode — reviews just dropped? Don't panic. ARIS reads every concern, builds a strategy, and drafts a rebuttal that's grounded, structured, and under the character limit:
/rebuttal "paper/ + reviews" — venue: ICML, character limit: 5000
Three safety gates — rebuttal will NOT finalize if any fails:
- 🔒 No fabrication — every claim maps to paper/review/user-confirmed result
- 🔒 No overpromise — every promise is user-approved
- 🔒 Full coverage — every reviewer concern is tracked
Two outputs: PASTE_READY.txt (exact char count, paste to venue) + REBUTTAL_DRAFT_rich.md (extended version for manual editing).
Show rebuttal parameters — venue, character limit (required), quick mode, auto experiment, stress test rounds, followup rounds
| Parameter | Default | What it does |
|---|---|---|
venue |
ICML |
Target venue (ICML/NeurIPS/ICLR/CVPR/ACL/AAAI/ACM) |
character limit |
— | Required. Hard character limit for rebuttal text |
quick mode |
false |
Stop after parsing + strategy (Phase 0-3). See what reviewers want before drafting |
auto experiment |
false |
Auto-run supplementary experiments via /experiment-bridge when reviewers ask for new evidence |
max stress test rounds |
1 |
How many times GPT-5.6-Sol xhigh stress-tests the draft |
max followup rounds |
3 |
Per-reviewer follow-up round limit |
After acceptance — your paper is in, now prepare the presentation:
/paper-slides "paper/" # → Beamer PDF + PPTX + speaker notes + Q&A prep
/paper-poster-html "paper/" # → measurement-gated HTML/CSS poster → print-ready PDF
💡 From idea to paper to podium — one toolchain. 🌱
2. 📢 What's New
2026-07-14 —
🐞
/web-debug-search(Issue #211). Adds a focused debugging/discovery workflow for GitHub Issues and Discussions: exact and normalized error-string matching, version compatibility tracking, and explicit failure handling. Results are labeled for debugging only and are not paper-citation evidence.2026-07-14 —
--list-groups,--groups X,Y,--skills X,--exclude Y, or a bare-TTY checkbox picker), with hard pipeline deps auto-included. Updates now confirm each NEW upstream skill individually (--add-new/--skip-newfor scripting; declines are remembered and never re-asked). Also fixes copy installs (~/.claude/skills) losing helper-script resolution, via a new~/.aris/repopointer file. ⚠️ Backward compatible —--quietfresh installs still install everything; run any installer/updater once to pick up the pointer file. Selective install →2026-07-12 —
/integrity-forensicsskill: a SHA-pinned thin launcher runs Anti-Autoresearch's hostile-reviewer sweep (evidence ledger, nine auditor dimensions, numeric core, rules-only adjudicator) on your paper first. The verdict feeds a typed gate — flags can block a submission, a clean sweep is recorded as "no new blocker" (never an acquittal) — and findings close only with typed, hashed evidence or a recorded human waiver (rewording the flagged sentence doesn't count; the ledger notices)./paper-writingruns it by default at submission assurance (— self_forensics: falseopts out; the Codex mirror is opt-in and limited to upstream's deterministic slice, which can flag but never say CLEAN). ⚠️ First run clones and validates the pinned upstream (needs network); runbash tools/smart_update.sh --apply.Earlier updates (2026-03-12 — 2026-07-10, 78 entries)
2026-07-10 —
ultralevel (#354). codex-cli 0.144.1 addedmax/ultrareasoning abovexhigh; ARIS reviews now default togpt-5.6-sol, with the seven heavyweight verdicts (/proof-checker,/kill-argument,/research-review,/experiment-audit,/paper-claim-audit,/result-to-claim,/meta-apply) atultraand everything else atxhigh. Older codex-cli or no model access steps down automatically (5.6-sol → 5.5, bothxhigh) — never belowxhigh, never on a mere timeout. Also fixed:/result-to-claimnow stops honestly instead of judging its own results when the reviewer is unreachable. ⚠️ Upgrade codex-cli to ≥ 0.144.1, restart the session (MCP reloads only then), and runbash tools/smart_update.sh --apply.2026-07-03 —
bash tools/smart_update.sh --applyto pull.2026-07-02 —
/meta-optimizeasks what can be removed, and/paper-writingagrees on a clear "done" checklist before drafting starts. ⚠️ Runbash tools/smart_update.sh --applyto pull.2026-06-20 —
/idea-creatorrun vanished on re-generation — because wiki pages were written freehand, a prose step the model skips on a re-prompt. Each layer now has a dedicatedresearch_wiki.pywriter joiningingest_paper:add_claim(claims born at/proof-checker),upsert_idea(/idea-creator),add_experiment(/result-to-claim) — each guarded by a drift-check so it can't silently regress to dead code. A claim'sstatusis now a strict proof axis (verified/refuted/unproven/…) while experiment support is carried bysupports/invalidatesedges (closing a latent contradiction the shared validator rejected), and the Codex-CLI skill mirror is synced to match. Zero behavior change when noresearch-wiki/is present.2026-06-19 —
2026-06-07 —
/paper-poster-htmlis now the default poster pipeline; the old LaTeX/paper-posteris retired. It builds the poster as one HTML/CSS file at the venue's real print size, then runs measured layout and asset checks before a content reviewer sees it, so review time goes to the science instead of crooked columns. It also ships templates, reusable poster components, and venue token packs; the core gate machinery was adapted from posterly (MIT, by @Chenruishuo). ⚠️/paper-posternow redirects to/paper-poster-html; the LaTeX pipeline lives only in git history.2026-05-31 —
2026-05-31 —
— reviewer: agyroutes review through the Antigravity CLI for users without Codex MCP / Oracle — fail-closed on the cross-model invariant (recovers + verifies the real Gemini-family model, refuses non-Gemini, binds the recovered transcript to the call via a user-event nonce). Wired intoreviewer-routing.md.2026-05-29 —
shared-referencesdocs decouple breadth from verdict:fan-out-pattern.md(skills generate candidates across same-family Claude subagents — Tier-1 Workflow / Tier-2 Agent / Tier-3 sequential — all ending in the identical cross-model jury),acceptance-gate.md("a loop can DRIVE, it cannot ACQUIT" — self-judge execution-completeness, never quality/correctness), andexternal-cadence.md(/loop&CronCreateare fire-control, never a jury). Wired into/idea-creator,/research-lit,/proof-checker,/kill-argument(fan-out) plus 16 skills (cadence fence/affordance). Also stripped 48 vestigialAgentgrants (least-privilege + a drift-check guard), fixed/idea-creator's same-family idea pre-filter, and reconciled an/auto-review-loopOR→ANDstop-condition inconsistency. Non-ultracode users benefit immediately — fan-out degrades to sequential with the same final jury.2026-05-28 —
/render-htmltoolchain can produce.2026-05-26 —
/idea-discovery,/auto-review-loop,/research-pipeline,/kill-argument,/proof-checker,/paper-claim-audit,/citation-audit,/rebuttalnow auto-render their primary MD artifact to a single-file HTML view via/render-html. Cost-tiered: interim views use--no-review, audit-class / reviewer-facing deliverables keep the full Codex render-fidelity gate. Default on (RENDER_HTML = true); per-skill opt-out. Failures non-blocking — source MD stays canonical.2026-05-26 —
/wiki-enrich(#247 by @hungchun0201) fills paper TODOsingest_paperleaves as scaffolds — Karpathy LLM-wiki principle, fetch chain alphaxiv→deepxiv→arXiv. Mirror drift checker + CI (#241 by @VeraPyuyi) keeps main↔mirror in sync./research-pipelineStage 2/3 unified into/experiment-bridgedelegation (#243 by @ZBigFish) — old inline was a strict subset of the bridge. Windows PowerShell installer parity with reparse-chain inside-repo guard +-FromOldlegacy migration + Windows CI matrix (#242 by @VeraPyuyi). Plusmanual-reviewMCP (#246 by @ZBigFish) — third reviewer backend— reviewer: manualfor zero-cost cross-model review (paste prompt to any non-Claude model: DeepSeek / Kimi / ChatGPT / Gemini / local llama); cross-model invariant guarded by bilingual UI banner + per-session token auth + fail-closed when MCP unavailable.2026-05-17 —
SKILL.md+ MCP support, no skill mirror needed. Installer (install_aris_copilot.sh) + smart-updater + 13-test suite. Community contribution by @EarendelH (#229, closes #214 / #227 / #203).2026-05-17 —
🛠 Tools-stability roadmap (Phase 1+2+3) complete (closes #176 / #177 / #178). Community reported that helper scripts weren't propagating into user projects after
install_aris.sh. Phase 1 — every SKILL.md caller of the 10 canonical helpers now resolves via the strict-safe 3-layer chain.aris/tools/→tools/→$ARIS_REPO/tools/documented inintegration-contract.md§2 (which also defines 5 failure policies A/B/C/D1/D2/E). Phase 2 — new advisory CI lint catches hardcodedpython3 tools/foo.pypatterns in PR-modified SKILL.md (advisory only, never fails CI). Phase 3 — three single-owner helpers (figure-spec,paper-illustration-image2,experiment-queue) moved into their SKILL'sscripts/subdirectory; owner SKILLs use Layer 0${CLAUDE_SKILL_DIR}/scripts/ahead of the canonical chain; legacytools/paths retained asos.execvPython forwarding shims. ⚠️ Existing users: no action needed — legacytools/entries are now shims. If you haven't runinstall_aris.shsince 2026-04-30, one idempotent rerun catches everything up.2026-05-14 —
/paper-plan+/paper-writelearnGAP_REPORT.md+<!-- DATA_NEEDED -->discipline (#217). When— style-ref:is set and the user's project has structural assets (figures/,results/,NARRATIVE_REPORT.md, etc.),/paper-planemits a Gap Report mapping the exemplar's section topology + density (fromstyle_profile.md) against your actual assets — surfacing slots you have no evidence to fill (e.g., "exemplar has 3×4 ablation table, you have no ablation data"). Then/paper-writewrites<!-- DATA_NEEDED: <Slot ID> — <description> -->HTML comments instead of fabricating content at missing slots — invisible in the compiled PDF,grep-friendly for human triage //experiment-bridgefollow-up. Narrow carve-out from the "no placeholders" rule, scoped to GAP_REPORT-listed slots only. Original idea by @zhangpelf.2026-05-14 —
⚙️ Default reviewer model:
gpt-5.4→gpt-5.5across ~30 SKILL.mdREVIEWER_MODELdefaults. Codex MCP has routedgpt-5.5as the default since 2026-04-24; this catches the docs up to runtime. ⚠️ Behavior changes: (a).aris/traces/*JSONs from prior runs are not reproducible — re-runs on 5.5 may emit differentWARN/FAILverdicts on borderline cases (reviewer-quality lift, not regression). (b) ChatGPT Plus/Pro monthly quotas drain faster under heavy use. Fallback: pass— reviewer-model: gpt-5.4per invocation, or pinREVIEWER_MODEL = gpt-5.4per skill. Oracle Pro tier (routed via— reviewer: oracle-pro) is a separate path and unaffected.2026-05-13 —
tools/verify_papers.py+ Pre-Search Verification Protocol — anti-hallucination filter for literature-facing skills. New helper does 3-layer fallback verification (arXiv batch API up to 40 IDs/request → CrossRef DOI lookup → Semantic Scholar fuzzy title match, default 0.6 word-overlap) and emits 4-state per-paper status (verified/unverified/verify_pending/error) plus a top-level verdict aligning withassurance-contract.md(PASS/WARN/BLOCKED/ERROR). Transient failures (5xx, timeouts, 429) are taggedverify_pendingand excluded from the hallucination rate so network blips don't get conflated with fabricated references. Per-project cache at<project>/.aris/cache/verify_papers.jsonwith 30-day TTL; canonical key priorityarxiv:{id_without_version}→doi:{lowercase}→title:{sha1[:16]}. NewPre-Search Verification Protocolsubsection inshared-references/citation-discipline.mdmakes the split explicit: this protocol is the fast filter between SEARCH (Step 1) and full VERIFY (Step 2);/citation-auditand/paper-claim-auditremain the submission-time audit gates and are not replaced./research-litgets a mandatoryStep 1.5: Verify Candidate Paperscalling the helper;/idea-creatorand/novelty-checkadd a Key Rule reference for cited Closest Prior Work / landscape entries. Unverified papers are retained in output tagged[UNVERIFIED](retention-over-silent-removal) so search-quality issues stay visible. SetARIS_VERIFY_EMAILin your shell to lift CrossRef to the polite-pool rate. Original signal from @YiwenZhu77 in #120 — landed via clean reimplementation rather than direct merge (PR was 5 weeks old + scope creep into figure-style).2026-05-06 —
/paper-talkworkflow +/slides-polishskill — end-to-end conference talk pipeline./paper-talkorchestrates paper → slide outline → Beamer + PPTX → per-page polish → assurance audits → final report (sister to/paper-writing,/paper-poster); composes/paper-slides,/slides-polish, plus/paper-claim-audit+/citation-auditwhenassurance: conference-ready./slides-polishis the post-generation visual pass: per-page Codex review against a reference PDF + a fix-pattern catalog (PPTX font scaling 1.5-1.8× for projector-readable size, text-frame resize after font bump, banner-as-tcolorbox, italic style leak guard, em-dash spacing, Chinese EA font hint via PingFang SC, anonymity placeholder discipline). Assurance ladderdraft / polished (default) / conference-readyis independent from the effort axis;effort: lite, assurance: conference-readyis legal and means "fast pipeline, every audit must emit verdict before final". Phase 4 staging adapter materializes slide text + speaker notes + talk script as a synthetic paper directory (.aris/paper-talk/audit-input/sections/*.tex+ symlinked.bib/results//figures/) so the existing audits run with their paper-shaped contracts and emit 6-state JSON verdicts pershared-references/assurance-contract.md.2026-05-05 —
/resubmit-pipeline— Workflow 5: text-only resubmit across venues (#208). Port a polished paper from one venue to another under hard constraints (no new experiments, no bib edits, no framework changes, never overwrite prior submissions). 5 phases: physical isolation → 5-layer anonymity check → audits (proof / claim / citation--soft-only) → microedits via/auto-paper-improvement-loop --edit-whitelistwith per-round diff gate → adversarial gate via/kill-argument→ final compile + Overleaf push via/overleaf-sync. Two prerequisite SKILL upgrades shipped in the same PR:/auto-paper-improvement-loop --edit-whitelist <path>(YAML schema with allowed/forbidden paths +forbidden_operationslikenew_cite/new_theorem_env/numerical_claim,forbidden_deletions,requires_user_approval_for,max_edits_per_round) and/citation-audit --soft-only(translates KEEP/FIX/REPLACE/REMOVE verdicts to text-rewrite proposals when bib is frozen; hallucinated citations getdrop_cite_in_body_onlyaction). MasterRESUBMIT_REPORT.jsonledger pershared-references/assurance-contract.md; 7-verdict failure mode table includingUSER_DECISIONruntime state.2026-05-05 —
/kill-argument— adversarial Attack-Adjudication review for theory papers (#206). Two fresh codex 5.5 + xhigh threads: Thread 1 writes the strongest 200-word rejection memo a senior area chair would produce; Thread 2 (independent adjudicator, NOT defender) reads the current paper and classifies each rejection point asanswered_by_current_text/partially_answered/still_unresolvedwith file:line evidence. Output:KILL_ARGUMENT.{md,json}, detect-only. Integrated as Phase 5.6 of/paper-writing(between claim-audit and citation-audit) and as the canonical implementation called from/auto-paper-improvement-loopStep 5.5 — replaces inline prompt in both places. Mandatory atassurance: submissionfor theory-heavy / scope-heavy papers; emitsNOT_APPLICABLEfor empirical papers without scope claims. Audit JSON isverify_paper_audits.sh-compatible (full schema pershared-references/assurance-contract.md, 6-state verdict). Catches the failure mode score-based reviews miss: when every local component is correct (numbers match, cites resolve, theorems prove) but the paper still oversells what it actually establishes.2026-05-04 —
/research-wikiand 8 caller skills now resolve helper via fallback chain (#204). Bug: afterbash tools/install_aris.shthe helper lives at.aris/tools/research_wiki.py(symlink), but skills hard-codedtools/research_wiki.pyand silently failed when invoked —research-wiki/stayed empty across full W1 runs. Fix: 3-layer chain (.aris/tools/→tools/→$ARIS_REPO/tools/) codified inshared-references/wiki-helper-resolution.md. The manual-copy workaround at<project>/tools/research_wiki.pyis layer 2, so users whocp-installed the helper as a temporary fix continue to work. ⚠️ Existing users: rerunbash tools/install_aris.shonce — also picks up a separate Python 3.9ImportErrorfix in the helper.2026-05-03 —
— style-ref: <source>for writer-side skills (#202)./paper-{plan,write,writing,illustration,poster,slides},/grant-proposal, and/auto-paper-improvement-loopaccept an optional— style-ref: <source>argument that mimics a reference paper's structural style (section ordering, theorem/figure density, sentence cadence, citation style) without copying its prose, claims, or terminology. Sources: local.texdir/file, local PDF, arXiv id (2501.12345orarxiv:2501.12345), HTTP/HTTPS URL. Overleaf URLs/IDs are rejected — clone via/overleaf-sync setup <id>first. Default OFF; existing behavior unchanged when the flag is absent. Reviewer / auditor sub-skills (/proof-checker,/paper-claim-audit,/citation-audit, the improvement-loop reviewer) never see the style ref — cross-model review independence preserved. ⚠️ Existing ARIS users: the helper ships attools/extract_paper_style.py, distributed via the.aris/toolssymlink (install_aris.shPhase 0, added in #192). Re-runbash tools/install_aris.shonce to refresh the symlink and pick up the helper. Manual fallback:cp <ARIS-repo>/tools/extract_paper_style.py <your-project>/tools/. Without either, the writer skill aborts with a clear error pointing here.2026-05-02 —
gpt-5.5-pro/ DeepResearch from Node, via Chrome CDP Fetch interception + WebSocket second-leg streaming; ships an MCP server for Claude Code / Codex / Cline. Alternative implementation path to Oracle MCP for ARIS users invoking— reviewer: oracle-pro— same target capability (Pro-tier reviewer), different mechanics. Indexed under Awesome Community Skills & Extensions. 🌟 if you're using it!2026-05-02 —
/gemini-searchdefault bumped togemini-3-pro-preview(strongest Gemini, out-of-box). ⚠️ Action required: requiresgemini-cliv0.40+ (rungemini --version; upgrade withnpm i -g @google/gemini-cliif older). Legacy override:/gemini-search "topic" — model: gemini-2.5-pro. Other overrides:gemini-3-flash-preview(faster),auto-gemini-3(load-routed). (b)/idea-discoveryPhase 1 now includes Gemini in its literature survey by default (#199) — auto-injects— sources: all, geminiinto/research-litunless the user passed an explicit— sources:; graceful skip ifgemini-clinot installed. (c) Oracle MCP upstream PR queue (steipete/oracle/pulls) is the first triage stop when invoking— reviewer: oracle-pro(especiallyo3-deep-research/gpt-5.5-pro) — ARIS does not vendor Oracle MCP; check upstream first if behavior surprises you (reviewer-routing.md)2026-05-02 —
install_aris.shcreates optional.aris/toolssymlink (#192, closes #174) — Phase 0 of the 4-step tools-stability plan (#174 → #176 → #177 → #178); idempotent, zero impact until rerun. (b)/experiment-queueorchestration paths repaired (#193) — first real user of the symlink; 7 cascading bugs fixed via 3 rounds of Codex MCPgpt-5.5xhigh audit. Pure prose + docstring;queue_manager.pylogic untouched. Windowsinstall_aris.ps1parallel update tracked as follow-up2026-05-02 —
/citation-audit --uncitedsurfaces bib entries with no\cite{}reference (detect-only)./proof-checker --deep-fixadds a repair-grade plan to the Phase 1 reviewer prompt (corrected statement / patch plan / closure tests + Schur/quadratic-form algebra sanity)./proof-checker --restatement-checkadds Phase 3.6 cross-location theorem drift detection (6 drift signatures). Zero behavior change when flags unset. Plus doc PRs #190 (thread-policy) + #191 (auto-loop xref). Delegated-agent + maintainer-fixup pattern; Codex MCPgpt-5.5xhigh review caught 6+ blockers2026-05-01 —
/research-lit(#175, community contribution by @stdAri). Two opt-in sources:/gemini-search(AI-driven discovery viajamubc/gemini-mcp-toolMCP) and/openalex(250M+ work open citation graph, no API key). Triggered via— sources: geminior— sources: openalex; zero behavior change when defaultall(both excluded). Maintainer fixups: corrected@google/gemini-clinpm name; addedtry/except ImportError+ bash preflight for graceful OpenAlex skip whenrequestsmissing2026-04-30 —
/rebuttalper-reviewer thread mode + transferable patterns (SKILL.md). AddsVENUE_MODE(single_document|per_reviewer_thread) for OpenReview-style venues,reviewer_priority: pivotalrouting,structural_distinctionresponse mode, 5 reviewer-defensive heuristics, 2 Phase 5 lints, and severity-scaled stress rounds. DefaultVENUE_MODE = single_documentkeeps ICML-style behavior — zero change for existing users. Three rounds of cross-model review before/after merge2026-04-30 —
skills/skills-codex/now mirrors all 67 mainline skills; replacesmcp__codex__codexreviewer path with Codex-nativespawn_agent+send_input. Newtools/install_aris_codex.sh+tools/smart_update_codex.shhandle project-local symlinks with manifest tracking. Anti-drift:tests/test_codex_skill_mirror.py+tests/test_codex_install_update.py(26 failure paths). Open discussion in #1842026-04-24 —
/paper-illustration-image2— Codex-native image generation as Phase 2b illustration backend (#166, community contribution by @kbr19-thu 清华). Uses ChatGPT Plus/Pro quota via local Codex app-server MCP bridge — noGEMINI_API_KEYrequired. Triggered by/paper-writing — illustration: codex-image2; default staysfigurespec(zero behavior change). Async-only API, sandboxed writes tofigures/ai_generated/, integration-contract-compliant helper. Marked experimental (Codex debug app-server is unstable upstream)2026-04-21 —
research_wiki.py,/research-wiki). Fixes user-reported bug where/research-wiki initleftpapers/empty forever (ingestsubcommand had no implementation; paper-reading skills had no wiki hook). New canonicalpython3 tools/research_wiki.py ingest_paperhelper owns slugging / metadata fetch / dedup / page render; all 6 paper-reading skills wired to it. Manual backfill viasync --arxiv-idsorsync --from-file. Ships withintegration-contract.mdformalizing the six-component pattern every cross-skill integration must follow2026-04-21 —
— effort: beast | maxnow really runs mandatory audits (assurance-contract.md,tools/verify_paper_audits.sh). Fixes silent-skip of/proof-checker//paper-claim-audit//citation-auditat high effort. Newassuranceaxis (draft|submission) independent fromeffort:lite/balanced→draft(zero behavior change),max/beast→submission. At submission the 3 audits emit a JSON artifact with 6-state verdict;paper-writingPhase 6 runs the external verifier as source of truth (non-zero exit blocks Final Report). SHA256 input hashing catches stale audits. Escape hatch:— effort: beast, assurance: draft2026-04-20 — 🩹 Project install: flat layout + manifest tracking — fixes a real bug where the previous nested install (
.claude/skills/aris/) hid skills from Claude Code's slash-command discovery (CC only scans one directory level). Anyone who raninstall_aris.shbefore this date was silently affected. Newinstall_aris.shcreates one symlink per skill at.claude/skills/<name>, writes a versioned manifest to.aris/installed-skills.txt, and is re-runnable to reconcile new/removed upstream skills. Defense-in-depth: 13 safety rules (no-symlinked-parents, exact-target revalidation, slug regex, atomic same-dir manifest rename, no-overwrite-real-files, mkdir-based portable lock, ADOPT for crash recovery, …). Granular--adopt-existing/--replace-linkflags replace the all-or-nothing--force. Migration paths:--from-oldfor legacy nested symlink,--migrate-copy keep-user|prefer-upstreamfor legacy nested copy.smart_update.sh --target-subdir .claude/skills/arisis now deprecated with a redirect toinstall_aris.sh. Stale-file bug incp -roverlay also fixed (nowrm -rf && cp -rfor safe-update path)2026-04-19 — 🔗
/overleaf-sync— two-way bridge between local ARIS paper directory and an Overleaf project via the official Overleaf Git bridge (Premium). Lets collaborators keep editing in the Overleaf web UI while ARIS audit/edit pipelines (/paper-claim-audit,/citation-audit,/auto-paper-improvement-loop) keep running locally. Sub-commands:setup(one-time, user-driven so the agent never sees the token) /pull(with diff-protocol — flags half-sentences, typos, claim/cite changes that should re-trigger audits) /push(with confirmation gate before writing to shared Overleaf state) /status(3-way divergence check). Token never touches the agent or any file — primed once into macOS Keychain via the user's terminal, then auth-free for all subsequent agent operations2026-04-19 — 📚
/citation-audit— fourth and final layer of the evidence-and-claim assurance stack (experiment-audit→result-to-claim→paper-claim-audit→citation-audit). Fresh cross-family reviewer (gpt-5.4 via Codex MCP) with web/DBLP/arXiv lookup verifies every\cite{...}along three independent axes: existence (paper resolves at claimed arXiv ID/DOI/venue), metadata correctness (authors/year/venue/title match canonical sources), and context appropriateness (the cited paper actually establishes the claim it supports — the most diagnostic check). Per-entry verdicts: KEEP / FIX / REPLACE / REMOVE. Auto-integrated into Workflow 3 Phase 5.8 as the pre-submission bibliography gate. Empirical motivation: in a real submission run, several real papers were cited in contexts they did not actually support, and at least one entry shipped withauthor = "Anonymous"— none caught by metadata-only checks2026-04-17 — 🔀
/experiment-queueintegrated into Workflow 1.5 + research-pipeline —experiment-bridgePhase 4 Deploy now auto-routes by milestone job count: ≤5 jobs →/run-experiment, ≥10 jobs or phase dependencies →/experiment-queue(with OOM retry, stale-screen cleanup, wave-transition gating, crash-safe state). New--- batch: queueoverride for global force-queue mode. Large multi-seed sweeps fromEXPERIMENT_PLAN.md(e.g., 36-cellN × seed × n_traingrids) now get proper orchestration without manual queue invocation2026-04-17 — 🔗 Project-local symlink install (resolves #118) — new recommended default install.
bash tools/install_aris.shauto-detects platform (Claude Code / Codex CLI), creates.claude/skills/arisor.agents/skills/arissymlink to the ARIS repo, adds a managed<!-- ARIS:BEGIN -->block toCLAUDE.md/AGENTS.mdtelling the agent to use only project-local skills, and records install metadata in.aris/skill-source.txt. Solves the skill collision problem when ARIS is mixed with Superpowers / OpenHands / other community packs in the same global skill directory. PowerShell version (install_aris.ps1) ships with junction support for Windows.smart_update.sh --target-subdirflag added for.agents/skills/aris(Codex) project-copy installs; symlinked installs now correctly refusesmart_updateand direct users togit pull. Global install remains supported for power users2026-04-16 — 🎨
/figure-spec— deterministic JSON→SVG renderer packaged as a first-class skill. Preferred default for architecture/workflow/pipeline/audit-cascade figures in papers. Shape-aware edge clipping (rect/circle/ellipse/diamond), self-loops, curved edges, multi-line labels with CJK width estimation. Editable vector output, reproducible (same spec → same SVG), no external API. Phase 2b in Workflow 3 restored:illustration: figurespec(new default) /gemini/mermaid/false— 4-way illustration selector with complementary strengths2026-04-16 — ⚙️
/experiment-queue— SSH job queue for multi-seed/multi-config ML experiments. Designed from real 36-cell NeurIPS sweep pain points: OOM-aware retry with backoff, stale-screen cleanup, wave-transition race prevention, teacher→student phase dependencies, crash-safe scheduler that resumes from JSON state. Declarative grid specs expand automatically (e.g.,N × seed × n_train → 36 jobs). Configurableconda_hook+gpu_free_threshold_mibfor non-standard environments. Use for ≥10 jobs;/run-experimentstays for ad-hoc2026-04-15 — 🛡️ Paper Writing Pipeline Hardening — 10 empirically-motivated patches from a real NeurIPS run.
REVIEWER_BIAS_GUARD=true: every review round uses a fresh thread (codex-reply inflated 3→8/10). Reviewer Independence Protocol: no fix summaries to reviewer. Step 4.5 Restatement Regression Test: catches theorem drift across fix rounds. Step 5.5 Kill Argument Exercise: final-round adversarial attack/defense for theory papers. Location-aware overfull blocking. Theory Paper Consistency Pass in/paper-write. Enforced Bib Hygiene with DBLP/CrossRef validation. Phase 5.5 Mandatory Final Claim Audit as submission gate. Review Tracing Protocol: full prompt/response pairs saved to.aris/traces/for reviewer-independence audit (review-tracing.md,save_trace.sh). Inspired by community contribution from @李傲龍2026-04-15 — 🎨 FigureSpec Renderer v2 — deterministic JSON→SVG figure generation for academic papers. Shape-aware edge clipping (rect/circle/ellipse/diamond), self-loops, curved edges, multi-line labels with CJK width estimation, comprehensive validation (type checks, structure, palette). Went through 5 rounds of Codex review (3/10→7/10). All architecture and workflow diagrams in the ARIS tech report were generated with this pipeline. New
--- mode: vectorfor/paper-illustrationskill2026-04-14 — 📋
/paper-claim-audit— zero-context paper-to-evidence verification. Fresh reviewer with NO prior context compares every number in the paper against raw result files. Catches rounding inflation, best-seed cherry-pick, config mismatch, delta errors, scope overclaim. Auto-integrated into Workflow 3 (Phase 4.7). Completes the 3-layer audit chain:/experiment-audit(code) →/result-to-claim(science) →/paper-claim-audit(reporting). 👁️ Visual PDF review also added to improvement loop — reviewer now sees compiled PDF, not just LaTeX source. Inspired by Hermes Agent2026-04-13 — 🧿 GPT-5.4 Pro via Oracle —
— reviewer: oracle-proon any skill for the strongest available reviewer. API mode (fast) or browser mode (free). Supported on:/research-review,/auto-review-loop,/experiment-audit,/proof-checker,/rebuttal,/idea-creator,/research-lit. Default stays Codex xhigh. Not installed = zero impact. Setup →2026-04-13 — 🔬
/proof-checker— rigorous mathematical proof verification via cross-model review. 20-category issue taxonomy, two-axis severity, side-condition checklists (DCT/MCT/Fubini/IFT/...), counterexample red team, proof-obligation ledger. Auto-integrated into Workflow 3: detects\begin{theorem}and runs before improvement loop. Complements/proof-writer2026-04-10 — ⚡ Effort Levels —
— effort: lite | balanced | max | beast. Controls work intensity across all skills: papers found, ideas generated, review rounds, writing depth. Codex reasoning staysxhighalways.beast= every knob to maximum for top-venue sprints. Defaultbalanced= zero change for existing users. Details →2026-04-10 — 🔎 DeepXiv integration — progressive paper retrieval via DeepXiv CLI. Opt-in:
— sources: deepxivor— sources: all, deepxiv. Staged reading: search → brief → head → section.pip install deepxiv-sdkto enable. Community contribution by @DreamEnding2026-04-10 — 🛡️
/experiment-audit— cross-model experiment integrity verification. GPT-5.4 reads your eval scripts and results directly, checks for fake ground truth, self-normalized scores, phantom results, and scope inflation (#131, #57). Advisory — warns loudly, never blocks./result-to-claimauto-reads audit if present. New experiment-integrity.md shared reference. The executor must never judge its own integrity.2026-04-10 — 🧠
tools/smart_update.sh— intelligent skill updater. Compares local vs upstream, detects personal customizations (server paths, API keys), only updates safe skills.bash tools/smart_update.sh --apply2026-04-10 — 🏆 Community paper: UAV-CC — first community paper with full PDF archived. UAV change captioning benchmark for IEEE TGRS by @wxx827. Stack: Claude Opus 4.6 + Codex 5.4 xhigh + Cursor. Papers now archived in
community_papers/2026-04-08 — 📚
/research-wiki— persistent research knowledge base inspired by Karpathy's LLM Wiki. Accumulates papers, ideas, experiments, and claims across the entire research lifecycle with typed relationships. Wiki-aware hooks in/research-lit(ingest papers),/idea-creator(read wiki + write ideas back), and/result-to-claim(update claim status + trigger re-ideation). Failed ideas become anti-repetition memory. ARIS now learns from its mistakes.2026-04-05 — 🧬
/meta-optimize— outer-loop harness optimization for ARIS. Passively logs skill invocations, tool calls, failures, and parameter overrides via Claude Code hooks. Run/meta-optimizeto analyze accumulated usage data and propose SKILL.md improvements — reviewer-gated, user-approved. Inspired by Meta-Harness (Lee et al., 2026). ARIS now optimizes itself.2026-04-04 — 🔧 Codex Plugin deep integration —
/codex:rescuenow auto-invoked when experiments fail (Workflow 1.5) or LaTeX won't compile (Workflow 3). GPT independently diagnoses the bug before Claude retries — two AI debuggers are better than one. Optional:codex execpowers nightmare review,/codex:rescuepowers auto-debug. Setup →2026-04-03 — ☁️ Modal serverless GPU — no GPU?
gpu: modalin CLAUDE.md, one command (modal run launcher.py), no SSH, no Docker, auto scale-to-zero. $30/month free tier — enough to try ARIS experiments without any hardware.pip install modal && modal setupand go. Community contribution by @zeyuzhangzyz2026-04-03 — 🎮 Reviewer Difficulty Levels —
medium(default, unchanged),hard(reviewer memory + debate protocol),nightmare(GPT reads repo directly viacodex exec— Claude can't hide anything).— difficulty: nightmarefor maximum stress test before submission2026-03-30 — 🔥 Auto-debug & exhaust-before-surrender — experiment-bridge auto-diagnoses failures (OOM, import, CUDA, NaN) and retries up to 3×. Inspired by PUA
2026-03-30 — ☁️ Vast.ai GPU rental —
gpu: vastauto-rents cheapest GPU. By @YIHONG-JIN. 🔧 MiniMax M2.7 upgrade by @octo-patch2026-03-27 — 📄 IEEE venue support (9 families). 🔎 Semantic Scholar. By @ypd666
2026-03-26 — 📄 Document-based input —
RESEARCH_BRIEF.mdauto-detect2026-03-24 — 📝 Workflow 4:
/rebuttal— 7-phase pipeline, 3 safety gates2026-03-23 — 🔧
/training-check,/result-to-claim,/ablation-plannerintegrated. 📦compactmode. By @JingxuanKang & @couragec2026-03-22 — 📋 Templates — input templates for every workflow. 📄 7 venue templates — CVPR, ACL, AAAI, ACM MM added. 🛡️ Anti-hallucination fix — Workflow 2 enforces DBLP → CrossRef → [VERIFY]. 🔗
base repo— clone a GitHub repo as base codebase (— base repo: https://github.com/org/project)2026-03-22 — 🔍 Codex + Gemini review guide — Codex executes, Gemini reviews via local
gemini-reviewMCP bridge. CN2026-03-20 — 🚀 Antigravity adaptation guide — use ARIS skills in Google Antigravity (agent-first IDE). Community contribution by @PeppaPigw
2026-03-20 — 🖥️ Trae adaptation guide — use ARIS skills in Trae (ByteDance AI IDE). Community contribution by @Prometheus-cotigo. 🔢
formula-derivation— Community contribution by @Falling-Flower2026-03-19 — 🖼️
paper-poster— Conference poster. Community contribution by @dengzhe-hou2026-03-19 — 🔗 Workflow 1.5 upgraded —
/experiment-bridgeGPT-5.4 code review. 📊 W&B fix2026-03-18 — 🎤
paper-slides+ 🔁 Codex+Claude bridge + 🖱️ Cursor guide + 🤖 Codex CLI skills + 📝grant-proposal+ 🎨paper-illustration(Gemini) + 📊 CitationClaw2026-03-17 — 🔧 Git code sync + 🆓 ModelScope guide + parameter pass-through
2026-03-16 — 🔬
research-refine+experiment-plan— turn vague ideas into problem-anchored proposals with claim-driven experiment roadmaps. Now integrated into Workflow 1 (/idea-discovery). Community contribution by @zjYao362026-03-16 — 🇨🇳 Alibaba Coding Plan guide — one API key, 4 models (Kimi-K2.5 + Qwen3.5+ + GLM-5 + MiniMax-M2.7), dual-endpoint setup. Community contribution by @tianhao909
2026-03-15 — 🔀 Bring your own model! Any OpenAI-compatible API now works as reviewer via
llm-chatMCP server. GLM, MiniMax, Kimi, LongCat, DeepSeek all tested — zero Claude or OpenAI API needed2026-03-15 — 🐾 OpenClaw adaptation guide — use ARIS research workflows in OpenClaw without Claude Code slash skills
2026-03-15 — 📐
proof-writer— community skill for rigorous theorem proof drafting. 📚 Anti-hallucination citations —/paper-writenow fetches real BibTeX from DBLP/CrossRef instead of LLM-generated entries — on by default, zero install2026-03-14 — 📱 Feishu/Lark integration: three modes (off/push/interactive), mobile notifications for experiments, reviews, and checkpoints
2026-03-13 — 🛑 Human-in-the-loop: configurable
AUTO_PROCEEDcheckpoints across all workflows. Full autopilot or step-by-step approval2026-03-12 — 🔗 Zotero + Obsidian + local PDFs + arXiv/Scholar: multi-source literature search with cross-model novelty verification
2026-03-12 — 🚀 Three end-to-end workflows complete: one prompt → top-venue-style paper.
/research-pipelinechains idea discovery → auto review → paper writing autonomously2026-03-12 — 📝
/paper-writingworkflow: narrative report → structured outline → figures → LaTeX → compiled PDF → 2-round auto-improvement (4/10 → 8.5/10)
3. 🚀 Quick Start
# 1. Install skills — project-local symlinks (recommended)
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git
bash Auto-claude-code-research-in-sleep/tools/install_aris.sh ~/your-project # symlinks ARIS skills into <project>/.claude/skills/
# (prefer a global install instead? cp -r Auto-claude-code-research-in-sleep/skills/* ~/.claude/skills/)
# (don't need all 81? --list-groups / --groups X,Y / --skills X — see "Selective install" below)
# 1b. Update later (when upstream changes)
cd Auto-claude-code-research-in-sleep && git pull
bash tools/smart_update.sh --apply # updates safe skills, flags your personal customizations
# (NEW upstream skills need confirmation — --add-new to accept all non-interactively)
# Optional Codex mirror managed project install
bash tools/install_aris_codex.sh ~/your-codex-project
# Managed Codex project update
cd Auto-claude-code-research-in-sleep && git pull
bash tools/install_aris_codex.sh ~/your-codex-project --reconcile
# Copied Codex installs only (not for projects installed by install_aris_codex.sh)
bash tools/smart_update_codex.sh --local ~/.codex/skills
bash tools/smart_update_codex.sh --local ~/.codex/skills --apply
# 2. Set up Codex MCP (for review skills)
npm install -g @openai/codex
codex setup # set model to gpt-5.6-sol when prompted
claude mcp add codex -s user -- codex mcp-server
# 3. Use in Claude Code
claude
> /idea-discovery "your research direction" # Workflow 1 — be specific! not "NLP" but "factorized gap in discrete diffusion LMs"
> /experiment-bridge # Workflow 1.5 — have a plan? implement + deploy + collect results
> /auto-review-loop "your paper topic or scope" # Workflow 2: review → fix → re-review overnight
> /paper-writing "NARRATIVE_REPORT.md" # Workflow 3: narrative → polished PDF
> /rebuttal "paper/ + reviews" — venue: ICML # Workflow 4: parse reviews → draft rebuttal → follow-up
> /resubmit-pipeline "paper/" — venue: NeurIPS # Workflow 5: port a polished paper to a new venue (text-only, no new experiments)
> /paper-talk "paper/" — venue: ICLR # Workflow 6: paper → Beamer + PPTX talk + speaker notes + assurance audits
> /research-pipeline "your research direction" # Full pipeline: Workflow 1 → 1.5 → 2 → 3 end-to-end
> /research-wiki init # 📚 Enable persistent research memory (one-time)
> /meta-optimize # Meta: analyze usage logs → propose skill improvements
Don't need all 81 skills? See Selective install below for group/skill-level picks.
📚 Research Wiki (optional) — one-line init for persistent memory across sessions; see full Research Wiki section
Give ARIS persistent memory across sessions. Papers, ideas, failed experiments — nothing is forgotten:
# In Claude Code:
> /research-wiki init # creates research-wiki/ in your project
# That's it. From now on, /research-lit auto-ingests papers, /idea-creator reads
# the wiki before brainstorming (and writes ideas back), /result-to-claim updates
# claim status. Failed ideas become anti-repetition memory for future ideation.
🧬 Meta-Optimization (optional) — passive usage logging + /meta-optimize for data-driven SKILL.md improvements; see full Workflow M section
Run these in your normal terminal (not inside Claude Code) to enable passive usage logging:
# One-time setup in your project directory
mkdir -p .claude .aris/meta tools/meta_opt
cp Auto-claude-code-research-in-sleep/templates/claude-hooks/meta_logging.json .claude/settings.json
cp Auto-claude-code-research-in-sleep/tools/meta_opt/*.sh tools/meta_opt/
chmod +x tools/meta_opt/*.sh
# Then start Claude Code — hooks are active immediately
claude
Events are logged to both project-level (.aris/meta/events.jsonl) and global (~/.aris/meta/events.jsonl) logs. After 5+ workflow runs, run /meta-optimize to see data-driven improvement proposals. Use /meta-optimize --global to analyze trends across all your projects.
📝 Templates + 🔎 DeepXiv + 🔎 Exa + 🗑️ Uninstall — input templates, two extra literature sources, and the uninstall command
📝 Templates available! See templates/ for ready-to-use input templates for every workflow — research brief (Workflow 1), experiment plan (Workflow 1.5), narrative report (Workflow 3), paper plan (Workflow 3).
🔎 Optional: DeepXiv progressive retrieval
pip install deepxiv-sdk
Then use /deepxiv directly or opt into it from /research-lit with — sources: deepxiv or — sources: all, deepxiv.
🔎 Optional: Exa AI-powered web search
pip install exa-py
export EXA_API_KEY=your-key-here
Then use /exa-search directly or opt into it from /research-lit with — sources: exa or — sources: all, exa. Covers blogs, docs, news, and research papers with built-in content extraction.
🗑️ Uninstall: To remove ARIS skills without affecting your own personal skills:
cd Auto-claude-code-research-in-sleep && ls skills/ | xargs -I{} rm -rf ~/.claude/skills/{}
Show all 16 inline parameters and 14 override examples — AUTO_PROCEED / sources / arxiv download / DBLP_BIBTEX / code review / wandb / illustration / venue / base repo / gpu / compact / ref paper / effort / reviewer / difficulty (full per-skill defaults live in § Customization)
All pipeline behaviors are configurable via inline overrides — append — key: value to any command:
| Parameter | Default | What it does |
|---|---|---|
AUTO_PROCEED |
true |
Auto-continue at idea selection gate. Set false to manually pick which idea to pursue before committing GPU time |
human checkpoint |
false |
Pause after each review round so you can read the score, give custom modification instructions, skip specific fixes, or stop early |
sources |
all |
Which literature sources to search: zotero, obsidian, local, web, semantic-scholar, deepxiv, exa, gemini, openalex, or all. Note: semantic-scholar, deepxiv, exa, gemini, and openalex must be explicitly listed — not included in all |
arxiv download |
false |
Download top relevant arXiv PDFs during literature survey. When false, only fetches metadata (title, abstract, authors) |
DBLP_BIBTEX |
true |
Fetch real BibTeX from DBLP/CrossRef instead of LLM-generated entries. Eliminates hallucinated citations. Zero install |
code review |
true |
GPT-5.6-Sol xhigh reviews experiment code before GPU deployment. Set false to skip |
wandb |
false |
Auto-add W&B logging to experiment scripts. Set true + configure wandb_project in CLAUDE.md. /monitor-experiment pulls training curves from W&B |
illustration |
gemini |
AI illustration in Workflow 3: gemini (default, needs GEMINI_API_KEY), mermaid (free), or false (skip) |
venue |
ICLR |
Target venue: ICLR, NeurIPS, ICML, CVPR, ACL, AAAI, ACM. Determines LaTeX style file and page limit |
base repo |
false |
GitHub repo URL to clone as base codebase (e.g., — base repo: https://github.com/org/project). No code? Build on top of an open-source project |
gpu |
local |
GPU target: local (default), remote (SSH server), or vast (rent on-demand from Vast.ai — auto-provision, auto-destroy) |
compact |
false |
Generate compact summary files (IDEA_CANDIDATES.md, findings.md, EXPERIMENT_LOG.md) for short-context models and session recovery |
ref paper |
false |
Reference paper to build on (PDF path or arXiv URL). Summarized first, then ideas extend/improve it. Combine with base repo for paper+code workflows |
effort |
balanced |
Work intensity: lite (0.4x tokens), balanced (default), max (2.5x), beast (5-8x). Controls breadth/depth/iterations. Codex reasoning never drops below the tier floor (regular xhigh / deep audits ultra). See Effort Levels |
reviewer |
codex |
Reviewer backend: codex (GPT-5.6-Sol, tiered xhigh/ultra, default), oracle-pro (GPT-5.5 Pro via Oracle — strongest reasoning). See Setup → |
difficulty |
medium |
Reviewer adversarial level: medium (default), hard (+ memory + debate), nightmare (+ GPT reads repo via codex exec) |
/research-pipeline "your topic" — AUTO_PROCEED: false # pause at idea selection gate
/research-pipeline "your topic" — human checkpoint: true # pause after each review round to give feedback
/research-pipeline "your topic" — sources: zotero, web # only search Zotero + web (skip local PDFs)
/research-pipeline "your topic" — sources: all, deepxiv # default sources plus DeepXiv progressive retrieval
/research-pipeline "your topic" — sources: all, exa # default sources plus Exa AI-powered web search
/research-pipeline "your topic" — sources: all, gemini # default sources plus Gemini discovery
/research-pipeline "your topic" — sources: all, openalex # default sources plus OpenAlex citation graph
/research-pipeline "your topic" — arxiv download: true # download top arXiv PDFs during literature survey
/research-pipeline "your topic" — difficulty: nightmare # maximum adversarial review before submission
/research-pipeline "your topic" — effort: beast # all knobs to maximum — top-venue sprint
/research-pipeline "your topic" — effort: beast, reviewer: oracle-pro # beast + GPT-5.5 Pro reviewer — ultimate mode
/research-pipeline "your topic" — effort: lite # quick exploration, save tokens
/research-pipeline "your topic" — effort: max, review_rounds: 3 # max effort but cap review at 3 rounds
/research-pipeline "your topic" — AUTO_PROCEED: false, human checkpoint: true # combine options
/proof-checker "paper/" — reviewer: oracle-pro # Pro-level proof verification
Sandbox behavior and strict mode — control whether tool-call overrides may change the configured sandbox policy
The runtime's sandbox settings provide a configured baseline, while a tool request may also carry sandbox-related overrides. In the legacy compatibility mode, the effective request can therefore differ from the values written in settings.json.
To make the configured policy authoritative, enable strictMode:
{
"sandbox": {
"enabled": true,
"strictMode": true
}
}
With strictMode: true, the runtime ignores these LLM-supplied overrides: dangerouslyDisableSandbox, namespaceRestrictions, isolateNetwork, filesystemMode, and allowedMounts. The configured sandbox policy remains in effect even when a tool call requests a different value. This is opt-in so existing configurations keep their legacy behavior by default.
Run aris doctor to inspect the currently reported sandbox state. strictMode controls whether tool requests can override the runtime configuration; it does not replace the host operating system's permissions, filesystem protections, or network policy.
Codex MCP config + alternative reviewer routing — pin the model in ~/.codex/config.toml; pointers to Codex+Claude-review, Codex+Gemini-review, and the Codex mirror install chain
Important: ARIS skills pin the reviewer explicitly (model: gpt-5.6-sol + a per-tier reasoning effort) in every fresh call — your ~/.codex/config.toml no longer silently decides the reviewer. Still set model = "gpt-5.6-sol" there (recommended): it covers codex-native/mirror sessions and anything that doesn't pin. ultra/max effort needs codex-cli ≥ 0.144.1 + a session restart.
Want Codex to execute but Claude Code to review? See docs/CODEX_CLAUDE_REVIEW_GUIDE.md. That path installs the base skills/skills-codex/*, then overlays skills/skills-codex-claude-review/*, and routes review-heavy skills through the local claude-review MCP bridge.
Want Codex to execute but Gemini to review locally? See docs/CODEX_GEMINI_REVIEW_GUIDE.md and CN. That path installs the base skills/skills-codex/*, then overlays skills/skills-codex-gemini-review/*, and routes the reviewer-aware predefined skills through the local gemini-review MCP bridge using direct Gemini API by default.
Want the Codex mirror install chain? Use tools/install_aris_codex.sh for managed project installs and tools/smart_update_codex.sh for copied Codex installs. The Claude scripts remain the mainline entry points for Claude projects.
The base Codex mirror reviews through a fresh Codex spawn_agent: workflows may continue, but results are explicitly same-family / provisional. Only a Claude/Gemini overlay or deterministic verifier records accepted; submission reports therefore expose submission-ready: provisional | yes | no.
See full setup guide for details and alternative model combinations if you don't have Claude/OpenAI API.
4. ✨ Features
ARIS chains 81 composable skills across the whole research lifecycle — literature & novelty → idea discovery → GPU experiments → autonomous review loop → paper writing → peer review — with cross-model adversarial review (Claude executes · GPT-5.6-Sol xhigh reviews · optional GPT-5.5 Pro via Oracle), anti-hallucination DBLP/CrossRef citations, a persistent Research Wiki, flexible model backends, human-in-the-loop checkpoints, and optional Feishu / Zotero / Obsidian / GPU integrations.
🔥 And it scales to any agent's ultracode-style deep mode — the breadth/firepower pass adapts to the runtime (Claude Code ultracode + workflows on Opus 4.8, Codex spawn_agent, or plain sequential), feeding three roles: breadth · cross-model review → accuracy · research wiki → memory. However a loop is driven, it reports to the same cross-model jury + research wiki — it can drive, never acquit.
Full feature list
📊 81 composable skills — mix and match, or chain into full pipelines (
/idea-discovery,/auto-review-loop,/paper-writing,/research-pipeline). See full catalog →🔍 Literature & novelty — multi-source paper search (Zotero + Obsidian + local PDFs + arXiv/Scholar) + cross-model novelty verification
💡 Idea discovery — literature survey → brainstorm 8-12 ideas → novelty check → GPU pilot experiments → ranked report
🔄 Auto review loop — 4-round autonomous review, 5/10 → 7.5/10 overnight with 20+ GPU experiments
📝 Paper writing — narrative → outline → figures → LaTeX → PDF → auto-review (4/10 → 8.5/10), one command. Anti-hallucination citations via DBLP/CrossRef
🤖 Cross-model collaboration — Claude Code executes, GPT-5.6-Sol xhigh reviews. Adversarial, not self-play. Optional:
— reviewer: oracle-pro→ GPT-5.5 Pro via Oracle📝 Peer review — review others' papers as a conference reviewer, with structured scoring and meta-review
🖥️ Review-driven experiments — when GPT-5.6-Sol says "run an ablation", Claude auto-writes the script, rsyncs to GPU, runs in
screen, collects results, folds back into the paper. Configure server inCLAUDE.md(setup), or rent from Vast.ai withgpu: vast🔀 Flexible models — default Claude × GPT-5.6-Sol, also supports GLM, MiniMax, Kimi, LongCat, DeepSeek, etc. — no Claude or OpenAI API required
🛑 Human-in-the-loop — configurable checkpoints at key decisions.
AUTO_PROCEED=truefor full autopilot,falseto approve each step📱 Feishu/Lark notifications — three modes: off (default, recommended), push-only (webhook → mobile), interactive (approve/reject in Feishu). Zero impact when off
Preview: Push cards (group) & Interactive chat (private)
Push Only — group chat cards (experiment done, checkpoint, error, pipeline complete):
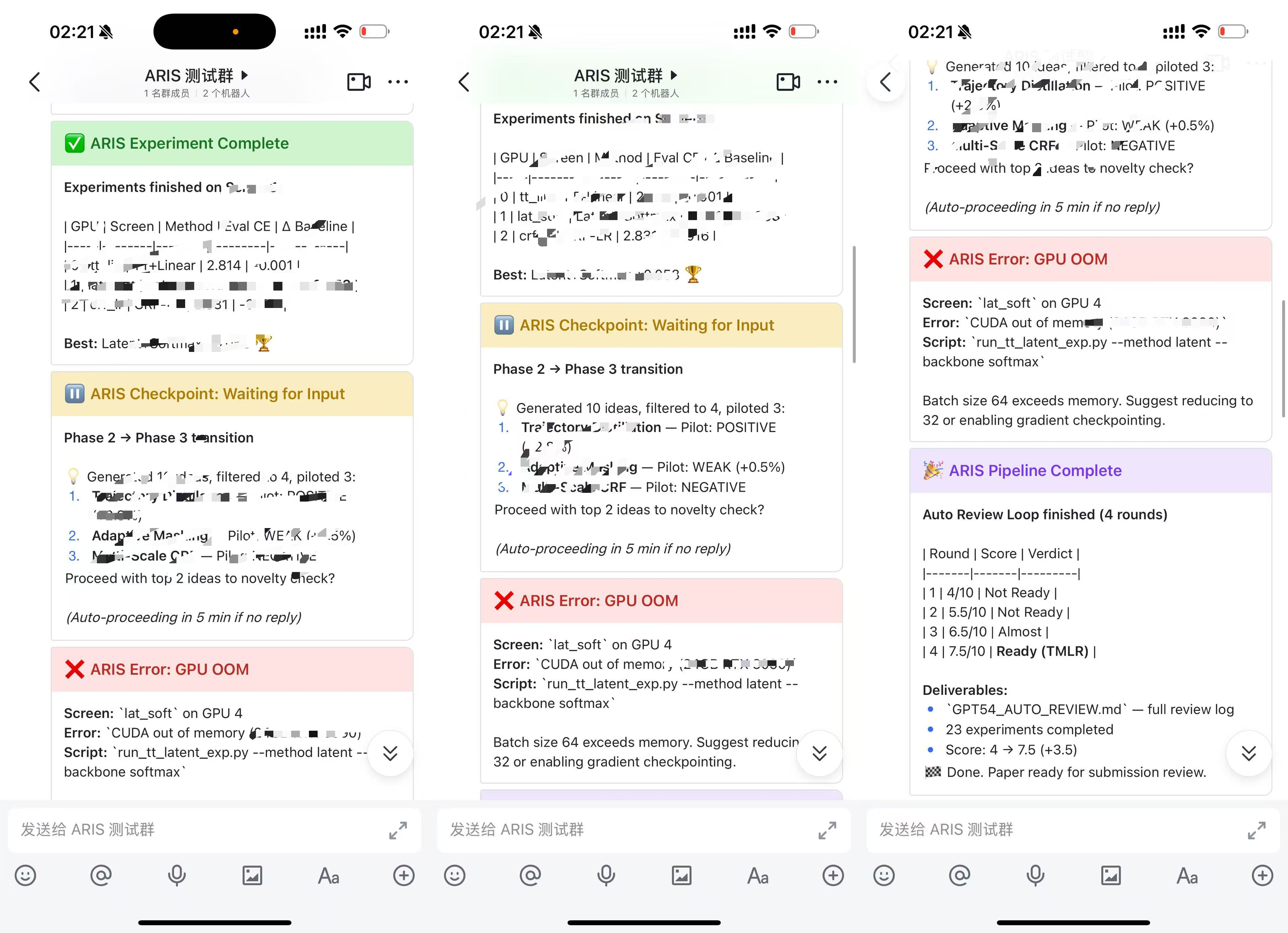
Interactive — private chat with Claude Code (approve/reject, custom instructions):
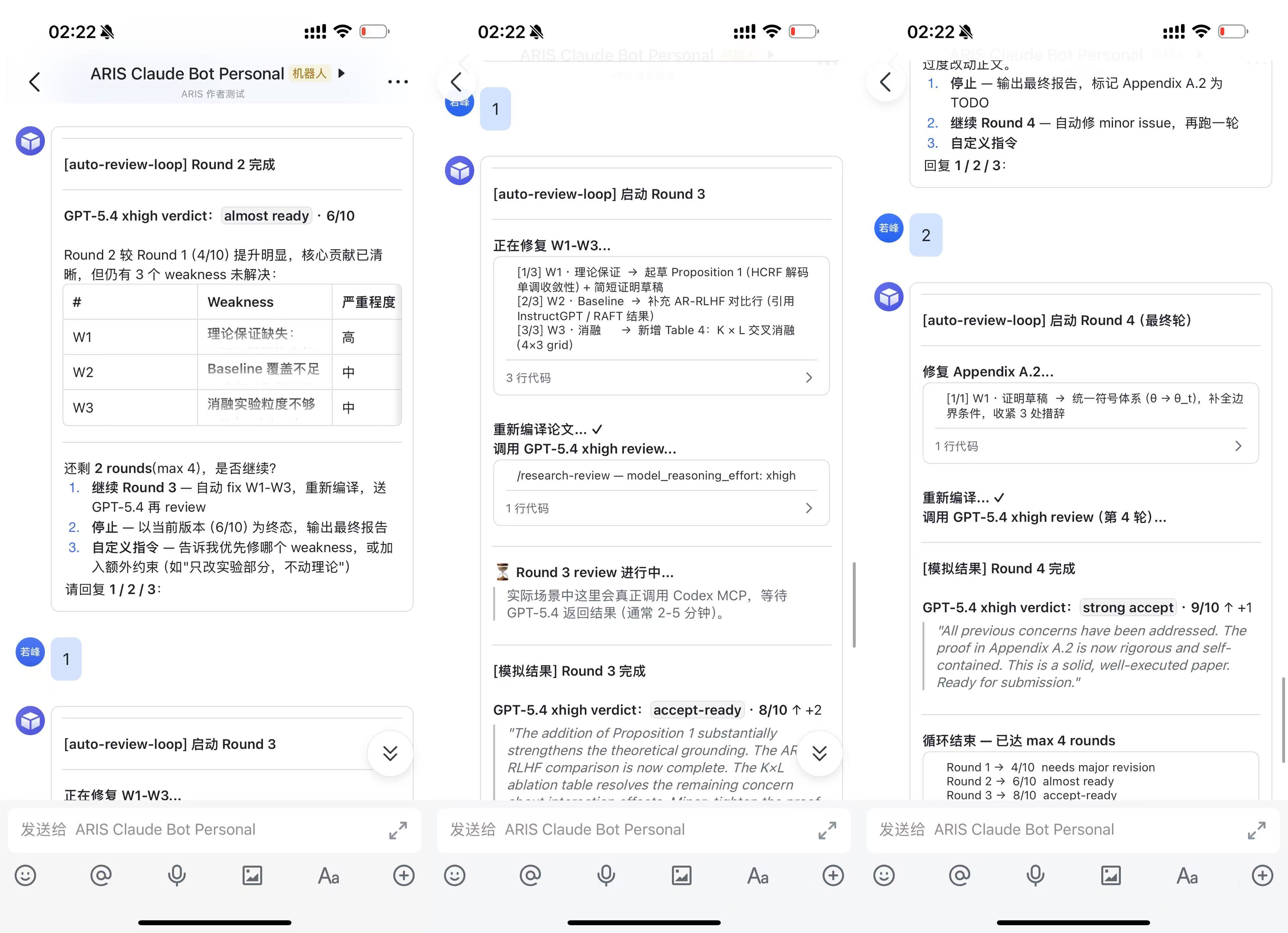
📚 Research Wiki — persistent knowledge base across papers/ideas/experiments/claims. Failed ideas become anti-repetition memory — ARIS gets smarter every run. Inspired by Karpathy's LLM Wiki
🧩 Extensible — domain-specific skills welcome! Add a
SKILL.mdand open a PR. See community skills likedse-loop(architecture/EDA)
ARIS ships 81+ skills across literature, ideation, experiments, audit, writing, talks, patents, and meta-utilities — the full catalog (role / category / requirements per skill) lives in docs/SKILLS_CATALOG.md to keep this README scannable.
Start here — common entry points (use case → skill)
| Use case | Start here |
|---|---|
| End-to-end research (idea → paper) | /research-pipeline |
| Idea discovery + method refinement | /idea-discovery |
| Run experiments from a plan | /experiment-bridge |
| Auto review → fix → re-review | /auto-review-loop |
| Narrative → polished PDF | /paper-writing |
| Reply to peer reviews | /rebuttal |
| Port a paper to a new venue | /resubmit-pipeline |
| Paper → conference talk | /paper-talk |
| Persistent research memory | /research-wiki |
| Patent drafting (CN / US / EP) | /patent-pipeline |
| ARIS optimizes itself | /meta-optimize |
→ Browse all 81 skills by category in the full catalog →
5. 📈 Score Progression (Real Run)
A real overnight 4-round run on an ML research project — the AI reviewer's score climbed 5.0/10 (borderline reject) → 7.5/10 (review-ready) as the loop autonomously ran 20+ GPU experiments, rewrote the narrative framing, and killed claims that didn't hold up, all without human intervention.
Round-by-round breakdown
| Round | Score | What Happened |
|---|---|---|
| Initial | 5.0/10 | Borderline reject |
| Round 1 | 6.5/10 | Added standard metrics, discovered metric decoupling |
| Round 2 | 6.8/10 | Key claim failed to reproduce, pivoted narrative |
| Round 3 | 7.0/10 | Large seed study killed main improvement claim |
| Round 4 | 7.5/10 ✅ | Diagnostic evidence solidified, submission ready |
6. 🏆 Community Showcase — Papers Built with ARIS
Real projects that used the full ARIS pipeline end-to-end. The scores listed are AI-review signals (CSPaper / Stanford Agentic Reviewer), not venue acceptances — and since ARIS optimizes through AI-review loops, high AI scores are an expected byproduct, not proof of acceptance (human reviewers still bring literature / venue / community judgment an AI reviewer misses). Used ARIS for a paper? Open an issue / PR to be featured!
Papers + their AI-review signals (3)
| Paper | AI-review signal | Submission status | Built by | Notes |
|---|---|---|---|---|
| CS Paper Submission | CSPaper 8/10 — AI reviewer recommendation: "Top 50% of accepted papers, clear accept" | Submitted to a CS conference; awaiting official feedback | @DefanXue & @Monglitay | Full ARIS pipeline: idea → experiments → auto-review → paper writing. The quote is from CSPaper's simulated review, not an official venue review. |
| AAAI 2026 Paper Submission | Stanford Agentic Reviewer 7/10 — AI reviewer recommendation: "Good paper, accept" | Submitted to AAAI 2026 Main Technical; awaiting official decision | @xinbo820-web | Pure Codex CLI (ARIS-Codex skills). The 7/10 signal comes from an AAAI-style Stanford Agentic Reviewer run, not an official AAAI acceptance result. |
| UAV-CC | Under review | Submitted to IEEE TGRS | @wxx827 | UAV change captioning benchmark. Claude Opus 4.6 (executor) + Codex GPT-5.5 xhigh (reviewer) + Cursor Opus 4.6 (assist). PDF → |
Reviewer screenshots
7. 🧩 Awesome Community Skills & Extensions
Domain-specific skills and external projects contributed by the community. PRs welcome — just add a skills/your-skill/SKILL.md and open a PR!
💡 How to use: Community skills are not auto-wired into core workflows. To use one, ask your executor (Claude Code / OpenClaw / etc.) to read the skill's
SKILL.md, then plug it into the appropriate workflow stage based on the description below.
🎉 Community Skills (15): research-refine · experiment-plan · research-refine-pipeline · grant-proposal · paper-poster (deprecated → paper-poster-html) · paper-slides · mermaid-diagram · proof-writer · comm-lit-review · dse-loop · idea-discovery-robot · formula-derivation · paper-illustration · writing-systems-papers · skills-codex
🌐 External Projects & Docs (14): rosetta · open-source-hardening-skills · CitationClaw · auto-hparam-tuning · paper-to-course · deep-research-skills · Antigravity Adaptation Guide · OpenClaw Adaptation Guide · Cursor Adaptation Guide · Codex+Claude Review Bridge · Trae Adaptation Guide · MiniMax-AI/cli · posterly · Claude Fleet
🙌 Thanks to every contributor! We fold the tables below to keep the README readable — but every skill and project here is equally valued. PRs always welcome!
🎉 Community Skills (15) — click to expand
| Name | Domain | Description | Codex MCP? |
|---|---|---|---|
🔬 research-refine |
General | Turn a vague idea into a problem-anchored, implementation-oriented method proposal. Best inserted between /idea-discovery and /auto-review-loop |
Yes |
🧪 experiment-plan |
General | Turn a refined proposal into a claim-driven experiment roadmap with ablations, budgets, and run order | No |
🧭 research-refine-pipeline |
General | One-shot chain: /research-refine → /experiment-plan for method refinement plus experiment planning |
Yes |
📝 grant-proposal |
General | Grant proposal drafting (KAKENHI/NSF/NSFC/ERC/DFG/SNSF/ARC/NWO). Chains /research-lit → /novelty-check → /research-review → /paper-illustration |
Yes |
🎤 paper-slides |
General | Conference talk slides (beamer → PDF + PPTX) with speaker notes, full talk script + Q&A prep. Auto slide count from talk type | Yes |
🖼️ paper-poster |
General | DEPRECATED — redirect stub to the core /paper-poster-html (measurement-gated HTML/CSS pipeline); the legacy LaTeX implementation lives in git history |
— |
📐 proof-writer |
ML Theory | Rigorous theorem/lemma proof drafting — feasibility triage, dependency maps, honest blockage reports | No |
📡 comm-lit-review |
Communications / Wireless | Domain-specific literature review — IEEE/ACM/ScienceDirect priority, venue tiering, PHY/MAC/transport/NTN taxonomy | No |
🏗️ dse-loop |
Architecture / EDA | Autonomous design space exploration — iteratively run, analyze, and tune parameters (gem5, Yosys, etc.) | No |
🤖 idea-discovery-robot |
Robotics / Embodied AI | Workflow 1 adaptation — grounds idea discovery in embodiment, benchmark, sim2real path, and real-robot safety constraints | Yes |
📐 mermaid-diagram |
General | Mermaid diagrams (20+ types) — free alternative to paper-illustration, no API key needed |
No |
🔢 formula-derivation |
General | Research formula development — derivation, verification, and LaTeX formatting | No |
🖥️ writing-systems-papers |
Systems | Paragraph-level blueprint for 10-12 page systems papers (OSDI/SOSP/ASPLOS/NSDI/EuroSys) — page allocation, writing patterns, self-check | Yes |
🎨 paper-illustration |
General | AI-generated architecture diagrams via Gemini, built on PaperBanana. Integrated into Workflow 3 | No |
🤖 skills-codex |
General | Codex CLI sync pack mirroring the main research skills (incl. result-to-claim, rebuttal, ablation-planner) + the shared-references/ support dir |
— |
🌐 External Projects & Docs (14) — click to expand
| Name | Domain | Description |
|---|---|---|
| 🪨 rosetta | Pro-tier ChatGPT MCP | Programmatic access to ChatGPT Pro / gpt-5.5-pro / DeepResearch from Node, via Chrome CDP Fetch interception + WebSocket second-leg streaming. Ships an MCP server for Claude Code / Codex / Cline — alternative implementation path to Oracle MCP for — reviewer: oracle-pro style high-tier review. Supports multi-turn, parallel concurrency, live token deltas, 15-min idle-timeout watchdog (long Pro thinks survive). MIT, by @SyntaxSmith |
| 🛡️ open-source-hardening-skills | DevOps / OSS | 10-skill pipeline to harden research code into production-ready open-source projects — audit, refactor, test, CI, docs, review |
| 📊 CitationClaw | General | Citation impact analysis — input paper title → citation crawling, scholar identification, tiered analysis, HTML dashboard |
| 🚀 Antigravity Adaptation Guide | General | Use ARIS skills in Google Antigravity — native SKILL.md support, dual model (Claude Opus 4.6 / Gemini 3.1 Pro), MCP setup, EN + CN guides |
| 🐾 OpenClaw Adaptation Guide | General | Use ARIS workflow methodology in OpenClaw — skill-to-stage mapping, file-based orchestration, no Claude Code CLI needed |
| 🖱️ Cursor Adaptation Guide | General | Use ARIS skills in Cursor — @-reference skills, MCP setup, workflow mapping, state file recovery across sessions |
| 🖥️ Trae Adaptation Guide | General | Use ARIS skills in Trae (ByteDance AI IDE) — EN + CN guides |
| 🎛️ auto-hparam-tuning | General | Automatic hyperparameter tuning — AI agent reads project, plans strategy, runs experiments, analyzes TensorBoard, learns from results. Hydra-based |
| 🔁 Codex+Claude Review Bridge | General | Codex executes + Claude reviews via local claude-review MCP bridge with async polling |
| 📚 paper-to-course | Education | Convert research papers (PDF/LaTeX) into interactive six-module HTML courses with formula breakdowns, literature timelines, quizzes, and glossary tooltips — single bundled file, no server needed |
| 🤖 MiniMax-AI/cli | General | Official MiniMax CLI — text, image, video, speech, and music generation + web search. skill/SKILL.md follows the agentskills.io standard. Drop-in companion for the Alt B (MiniMax reviewer) setup |
| 🔎 deep-research-skills | General / Web Search | Modular web-search strategy bundle — per-source playbooks for Stack Overflow, GitHub Issues / error-string debugging, Chinese tech communities (CSDN / 掘金 / 知乎 / V2EX / Tencent + Aliyun cloud forums), and general web (Reddit / HN / Dev.to / Medium). Complements ARIS's academic-paper-focused /research-lit stack with non-academic sources useful for debugging, version-compat tracking, and Chinese-language tech search. By @Weizhena |
| 🖼️ posterly | General / Posters | Academic conference posters as a single HTML/CSS file → print-ready PDF via headless Chromium (no LaTeX). A Claude Code skill — its gate machinery now powers ARIS’s default /paper-poster-html. By @Chenruishuo |
| 🛰️ Claude Fleet | Dashboard / DevEx | Local read-only dashboard for many concurrent Claude Code / Codex windows — triage (working / waiting-on-you / done), one-click Focus, ~50ms full-text search across transcripts, skill/memory analytics. By @tianyilt |
8. 🔄 Workflows
These skills compose into a full research lifecycle. Each workflow can be used independently or chained together:
- Exploring a new area (e.g., writing a survey)? Start with Workflow 1 →
/idea-discovery - Have a plan, need to implement and run? Workflow 1.5 →
/experiment-bridge - Already have results, need iterative improvement? Workflow 2 →
/auto-review-loop - Ready to write the paper? Workflow 3 →
/paper-writing(or step by step:/paper-plan→/paper-figure→/paper-write→/paper-compile→/auto-paper-improvement-loop) - Got reviews back? Need to rebuttal? Workflow 4 →
/rebuttal— parse reviews, draft safe rebuttal, follow-up rounds - Full pipeline? Workflow 1 → 1.5 → 2 → 3 → submit → 4 →
/research-pipeline+/rebuttal— from idea through submission and rebuttal - Want ARIS to remember and learn? 📚
/research-wiki init— persistent memory across sessions. Papers, ideas, failed experiments compound over time - Want ARIS to improve itself? Workflow M →
/meta-optimize— analyze usage logs, propose skill improvements, reviewer-gated
⚠️ Important: These tools accelerate research, but they don't replace your own critical thinking. Always review generated ideas with your domain expertise, question the assumptions, and make the final call yourself. The best research comes from human insight + AI execution, not full autopilot.
Full Pipeline 🚀
/research-lit → /idea-creator → /novelty-check → /research-refine → /experiment-bridge → /auto-review-loop → /paper-writing → submit → /rebuttal → accept! 🎉
(survey) (brainstorm) (verify novel) (refine method) (implement+deploy) (review & fix) (write paper) (send) (reply to reviewers)
├────────────── Workflow 1: Idea Discovery ──────────────┤ ├ Workflow 1.5 ─┤ ├── Workflow 2 ──┤ ├── Workflow 3 ──┤ ├── Workflow 4 ──┤
📚 research-wiki (persistent memory — papers, ideas, experiments, claims)
↕ reads before ideation, writes after every stage, failed ideas = anti-repetition memory
/meta-optimize (Workflow M — runs independently, improves ARIS itself)
↑ reads .aris/meta/events.jsonl (accumulated from all runs above)
Workflow 1: Idea Discovery & Method Refinement 🔍
"What's the state of the art? Where are the gaps? How do we solve it?"
Don't have a concrete idea yet? Just give a research direction — /idea-discovery handles the rest:
- 📚 Survey the landscape (recent papers, open problems, recurring limitations)
- 🧠 Brainstorm 8-12 concrete ideas via GPT-5.6-Sol xhigh
- 🔍 Filter by feasibility, compute cost, and quick novelty search
- 🛡️ Validate top ideas with deep novelty check + devil's advocate review
- 🧪 Pilot top 2-3 ideas in parallel on different GPUs (30 min - 2 hr each)
- 🏆 Rank by empirical signal — ideas with positive pilot results rise to the top
- 🔬 Refine the top idea into a problem-anchored proposal via iterative GPT-5.6-Sol review
- 🧪 Plan claim-driven experiments with ablations, budgets, and run order
The output is a ranked IDEA_REPORT.md plus a refined proposal (refine-logs/FINAL_PROPOSAL.md) and experiment plan (refine-logs/EXPERIMENT_PLAN.md) for the top idea. Dead-end ideas are documented too, saving future exploration.
Show W1 flow diagram and example command sequence — research-lit → idea-creator → novelty-check → research-refine → experiment-plan
┌─────────────────────────────────────────────────────────────────┐
│ Idea Discovery & Method Refinement │
│ │
│ /research-lit /idea-creator /novelty-check │
│ (find papers) (brainstorm) (verify novelty) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Scan │───▶│ Generate │────▶│ Check if │ │
│ │ local │ │ 8-12 │ │ idea is │ │
│ │ papers + │ │ ideas │ │ novel │ │
│ │ search │ │ + rank │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ Filter │────▶│ External │ │
│ │ by cost, │ │ LLM │ │
│ │ novelty │ │ evaluates│ │
│ └──────────┘ └──────────┘ │
│ │ │
│ /research-refine ▼ │
│ (refine method) ┌──────────┐ │
│ │ │ Freeze │ │
│ ▼ │ problem │ │
│ ┌──────────┐ │ anchor + │ │
│ │ Iterate │◀───▶│ refine │ │
│ │ until │ │ method │ │
│ │ score≥9 │ └──────────┘ │
│ └──────────┘ │ │
│ │ ▼ │
│ /experiment-plan ┌──────────┐ │
│ │ │ Claim- │ │
│ ▼ │ driven │ │
│ ┌──────────┐ │ experiment│ │
│ │ Plan │────▶│ roadmap │ │
│ │ runs │ └──────────┘ │
│ └──────────┘ │
│ │
│ Typical flow: │
│ 1. /research-lit "discrete diffusion models" │
│ 2. /idea-creator "DLLMs post training" │
│ 3. Review ranked ideas, pick top 2-3 │
│ 4. /novelty-check "top idea" (deep verification) │
│ 5. /research-review "top idea" (critical feedback) │
│ 6. /research-refine "top idea" (problem anchor + method) │
│ 7. /experiment-plan (claim-driven roadmap) │
│ 8. /run-experiment → /auto-review-loop │
└─────────────────────────────────────────────────────────────────┘
Skills involved: research-lit + idea-creator + novelty-check + research-review + research-refine-pipeline
💡 One-command shortcut:
/idea-discovery "your research direction"runs this entire workflow automatically.
🔄 Human-in-the-loop: Each phase presents results and waits for your feedback. Not happy? Tell it what's missing — it refines the prompt and regenerates. Trust the defaults? It auto-proceeds with the top-ranked option. You decide how hands-on to be.
⚙️ Pilot experiment budgets (max hours, timeout, GPU budget) are configurable — see Customization.
📝 Blog post: Claude Code 两月 NeurIPS 指北
Workflow 1.5: Experiment Bridge 🔗
"I have a plan. Now implement it, deploy it, and get me initial results."
Already have an experiment plan (from Workflow 1 or your own)? /experiment-bridge turns it into running code:
- 📋 Parse the experiment plan (
refine-logs/EXPERIMENT_PLAN.md) - 💻 Implement experiment scripts (reuse existing code, add proper argparse/logging/seeds)
- 🔍 GPT-5.6-Sol code review — cross-model review catches logic bugs before wasting GPU hours (
code review: trueby default) - ✅ Sanity check — run the smallest experiment first to catch runtime bugs
- 🚀 Deploy full experiment suite to GPU via
/run-experiment - 📊 Collect initial results and update the experiment tracker
Show W1.5 flow diagram — experiment plan → Claude implements → GPT-5.6-Sol code review → sanity check → GPU deploy → monitor → results
┌─────────────────────────────────────────────────────────────────┐
│ Workflow 1.5: Experiment Bridge │
│ │
│ EXPERIMENT_PLAN.md │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Claude │────▶│ GPT-5.6-Sol │────▶│ Sanity │ │
│ │ Code │ │ xhigh │ │ Check │ │
│ │ writes │ │ reviews │ │ (1 GPU) │ │
│ │ code │ │ code │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Collect │◀────│ Monitor │◀────│ Deploy │ │
│ │ results │ │ progress │ │ to GPUs │ │
│ │ │ │ (+ W&B) │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ Ready for /auto-review-loop │
└─────────────────────────────────────────────────────────────────┘
Skills involved: experiment-bridge + run-experiment + monitor-experiment
💡 One-command shortcut:
/experiment-bridgereadsrefine-logs/EXPERIMENT_PLAN.mdautomatically. Or point it to any plan:/experiment-bridge "my_plan.md".
⚙️
CODE_REVIEW,AUTO_DEPLOY,SANITY_FIRST,MAX_PARALLEL_RUNSare configurable — see Customization.
Workflow 2: Auto Research Loop 🔁 (sleep & wake up to results)
"Review my paper, fix what's wrong, repeat until it's good."
GPT-5.6-Sol reviews → identifies weaknesses → suggests experiments → Claude Code writes scripts, deploys to GPU, monitors results, rewrites the paper — all while you sleep. Just add your GPU server config to
CLAUDE.md.
- 🔍 Deep review — GPT-5.6-Sol xhigh reviews the current paper / claims / experiments and identifies weaknesses
- 🩹 Fix — Claude implements the fixes (rewrites sections, adds baselines, or runs new experiments via
/run-experiment); skips any experiment estimated > 4 GPU-hours and flags it for manual follow-up - 📊 Re-evaluate — collect results via
/monitor-experiment, update paper, feed back to the reviewer - 🔁 Repeat — until score ≥
POSITIVE_THRESHOLD(default 6/10) orMAX_ROUNDS(default 4) is hit; if context window fills mid-loop, the workflow auto-resumes fromREVIEW_STATE.json
Show W2 loop diagram — external review → implement fixes / run experiments → monitor results → repeat until threshold
┌─────────────────────────────────────────────────────────────┐
│ Auto Review Loop │
│ │
│ /research-review /auto-review-loop │
│ (single deep review) (autonomous loop) │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ External │──▶│ Implement│──▶│ Monitor │──▶ repeat │
│ │ LLM │ │ fixes │ │ results │ until │
│ │ reviews │ │ & run │ │ │ score ≥ 6 │
│ └──────────┘ │ experiments│ └──────────┘ │
│ └──────────┘ │
│ │
│ When reviewer suggests a new method direction: │
│ /novelty-check — verify idea isn't already published │
│ │
│ Supporting skills: │
│ /run-experiment — deploy to local/remote/vast.ai GPU │
│ /analyze-results — interpret experiment outputs │
│ /monitor-experiment — check progress, collect results │
└─────────────────────────────────────────────────────────────┘
Skills involved: auto-review-loop + research-review + novelty-check + run-experiment + analyze-results + monitor-experiment
💡 One-command shortcut:
/auto-review-loop "your paper topic"runs this entire workflow automatically.
Show W2 usage examples, reviewer difficulty levels, and full safety guarantees — topic/scope arguments, medium/hard/nightmare, 6 safety rules
What to pass as argument? A short topic or scope is enough — the skill automatically reads your project's narrative docs (NARRATIVE_REPORT.md), memory files, experiment results, and prior reviews to build the full context for GPT-5.6-Sol. Examples:
/auto-review-loop "factorized gap in discrete diffusion LMs"— broad topic, skill finds everything/auto-review-loop "focus on Section 3-5, our CRF results are weak"— targeted scope with hints/auto-review-loop— also works: skill reads project files and infers the topic
🎮 Reviewer Difficulty — control how adversarial the reviewer is:
| Level | What changes | Use when |
|---|---|---|
medium (default) |
Standard MCP review — same as before | Normal workflow |
hard |
+ Reviewer Memory (GPT tracks suspicions across rounds) + Debate Protocol (Claude rebuts, GPT rules) | Want tougher feedback |
nightmare |
+ GPT reads repo directly via codex exec (Claude can't filter what it sees) + adversarial verification |
Preparing for top venue, want maximum stress test |
/auto-review-loop "topic" — difficulty: nightmare # GPT reads your code and verifies claims itself
🛡️ Key safety features:
- 🔒 MAX_ROUNDS = 4 — prevents infinite loops; stops early if score threshold is met
- ⏱️ > 4 GPU-hour experiments skipped — won't launch massive jobs; flags them for manual follow-up
- 🧠 Prefer reframing over new experiments — when both can address a weakness, chooses the cheaper path
- 🪞 No hiding weaknesses — explicit rule: "Do NOT hide weaknesses to game a positive score"
- 🔧 Fix before re-review — must actually implement fixes before resubmitting; no empty promises
- 💾 Compact recovery — persists state (
REVIEW_STATE.json) after each round. If the context window fills up and auto-compacts mid-loop, the workflow reads the state file and resumes from where it left off — no human intervention needed
⚙️ MAX_ROUNDS, score threshold, and GPU limits are configurable — see Customization.
📝 Blog post: 开源 | 睡觉 Claude 自动跑实验改文
Workflow 3: Paper Writing Pipeline 📝
"Turn my research narrative into a submission-ready PDF." Requires a local LaTeX environment — see Prerequisites.
- 📝 Narrate — write
NARRATIVE_REPORT.md(claims, experiments, results, figure descriptions); seetemplates/NARRATIVE_REPORT_TEMPLATE.md - 🧭 Plan —
/paper-planbuilds the claims-evidence matrix + section plan - 📊 Figures —
/paper-figuregenerates data-driven plots and comparison tables from JSON/CSV - ✍️ Write —
/paper-writeproduces section-by-section LaTeX - 🔧 Compile —
/paper-compilebuilds the PDF, fixes errors, runs the page-limit check - ✨ Improve —
/auto-paper-improvement-loopruns 2 rounds of GPT-5.6-Sol content review + final format check
Show W3 architecture diagram and exact writing flow — NARRATIVE_REPORT → /paper-plan → /paper-figure → /paper-write → /paper-compile → improvement loop
┌─────────────────────────────────────────────────────────────┐
│ Paper Writing Pipeline │
│ │
│ /paper-plan /paper-figure /paper-write │
│ (outline) (plots & tables) (LaTeX draft) │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Claims- │───▶│ Generate │────▶│ Section │──┐ │
│ │ Evidence │ │ figures, │ │ by │ │ │
│ │ Matrix + │ │ tables, │ │ section │ │ │
│ │ Section │ │ LaTeX │ │ LaTeX │ │ │
│ │ Plan │ │ includes │ │ draft │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ │ │
│ │ /paper-compile │ │
│ │ (build PDF) │ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ NARRATIVE_REPORT.md ──► PAPER_PLAN.md ──► paper/ │ │
│ │ (input) (outline) (LaTeX+PDF)│ │
│ └──────────────────────────────────────────────────┘ │
│ │
│ Typical flow: │
│ 1. Write NARRATIVE_REPORT.md (from Workflow 2 results) │
│ 2. /paper-plan (claims-evidence matrix + section plan) │
│ 3. /paper-figure (comparison tables, training curves, etc.) │
│ 4. /paper-write (section-by-section LaTeX generation) │
│ 5. /paper-compile (build PDF, fix errors, page check) │
│ 6. /auto-paper-improvement-loop (review ×2 + format check) │
└─────────────────────────────────────────────────────────────┘
Skills involved: paper-plan + paper-figure + paper-write + paper-compile + auto-paper-improvement-loop + (post-acceptance) paper-poster-html + paper-slides
One-command shortcut:
/paper-writing "NARRATIVE_REPORT.md"runs this entire workflow automatically.
Input: A NARRATIVE_REPORT.md describing the research: claims, experiments, results, figures. The more detailed the narrative (especially figure descriptions and quantitative results), the better the output.
Output: A paper/ directory with LaTeX source, clean .bib (only cited entries), and compiled PDF. The PDF is labelled submission-ready only when run at — effort: max | beast (or explicit — assurance: submission) and tools/verify_paper_audits.sh reports green on the three mandatory audits (proof-checker, paper-claim-audit, citation-audit); see Assurance Gate below. At the default balanced level, the output is a reviewed draft.
Show W3 feature details — Claims-Evidence Matrix, figure modes, clean bib, Gemini API setup, ICLR end-to-end test
Key features:
- 📐 Claims-Evidence Matrix — every claim maps to evidence, every experiment supports a claim
- 📊 Auto figure generation — line plots, bar charts, comparison tables from JSON data
- 🧹 Clean bib — automated filtering removes uncited entries (948→215 lines in testing). Real BibTeX from DBLP/CrossRef instead of LLM-generated entries
- 📄 Flexible sections — 5-8 sections depending on paper type (theory papers often need 7)
- 🔍 GPT-5.6-Sol review — each step optionally reviewed by external LLM
- ✂️ De-AI polish — removes AI writing patterns (delve, pivotal, landscape...)
- 🎯 Page verification —
pdftotext-based precise check that main body fits page limit
⚠️ Figure generation scope:
/paper-figureauto-generates data-driven plots (training curves, bar charts, heatmaps) and comparison tables from JSON/CSV. For architecture diagrams and method figures:illustration: gemini(default) uses Claude→Gemini→Nano Banana Pro for publication-quality diagrams;illustration: mermaidgenerates Mermaid diagrams for free;illustration: falseskips AI figures entirely.Gemini API setup (for
illustration: gemini): Get your API key at Google AI Studio, then set it as an environment variable:export GEMINI_API_KEY="your-key". Or add to your shell profile (~/.zshrc/~/.bashrc). No other dependencies needed.
Tested end-to-end: Generated a 9-page ICLR 2026 theory paper (7 sections, 29 citations, 4 figures, 2 comparison tables) from a single NARRATIVE_REPORT.md — zero compilation errors, zero undefined references.
Auto Paper Improvement Loop ✨
After Workflow 3 generates the paper, /auto-paper-improvement-loop runs 2 rounds of GPT-5.6-Sol xhigh content review → fix → recompile, plus a final format compliance check, autonomously polishing the paper from rough draft to a reviewer-scored draft. Whether the result is tagged submission-ready is decided separately by the Phase 6 assurance gate (see Assurance Gate).
Show auto-paper-improvement benchmark — Score Progression on a real ICLR 2026 theory paper (4/10 → 8.5/10), plus Round 1/2/3 fix details
Score Progression (Real Test — ICLR 2026 theory paper):
| Round | Score | Key Changes |
|---|---|---|
| Round 0 | 4/10 (content) | Baseline |
| Round 1 | 6/10 (content) | Fixed assumptions, softened claims, renamed notation |
| Round 2 | 7/10 (content) | Added synthetic validation, stronger limitations |
| Round 3 | 5→8.5/10 (format) | Removed hero fig, appendix, compressed conclusion, float spacing |
Final: 8 pages main body (ICLR limit: 9), 0 overfull hbox, ICLR-compliant. +4.5 points across 3 rounds.
Round 1 fixes (6 items)
- CRITICAL — Assumption-model mismatch: A boundedness assumption contradicted the model's distributional family. Replaced with a tail-compatible assumption and added formal truncation bridge.
- CRITICAL — Theory-practice gap: Theory assumes idealized encoders, experiments use learned nonlinear encoders. Softened "validate" → "demonstrate practical relevance" and added explicit disclaimer.
- MAJOR — Missing quantitative metrics: Added parameter count table (latent vs total) with honest accounting of system cost.
- MAJOR — Theorem not self-contained: Added "Interpretation" paragraph listing all dependencies explicitly.
- MAJOR — Overclaim in novelty statement: Scoped a broad "first convergence guarantee" to precise conditions under which it holds.
- MAJOR — Notation confusion: Renamed a symbol that clashed with another key variable. Added Notation paragraph.
Round 2 fixes (4 items)
- MAJOR — Missing theory-aligned experiments: Added a synthetic validation subsection directly testing the two main theoretical predictions under controlled conditions.
- MAJOR — Overclaim softening: Replaced strong equivalence claims with appropriately hedged language across all files.
- MAJOR — Informal theoretical argument: Formalized an informal justification into a proper proposition with explicit error bounds.
- MINOR — Weak limitations: Expanded to explicitly list all assumptions and acknowledge missing standard evaluations.
Round 3 format fixes (8 items)
- Removed hero figure block (saved ~0.7 pages)
- Compressed conclusion from 15→9 lines
- Moved synthetic validation to Appendix A
- Moved comparison tables to Appendix B
- Fixed overfull hbox (85pt) with
\resizebox - Added compact float spacing (
\captionsetup,\textfloatsep) - Inlined centered question block in introduction
- Tightened
itemizeenvironments
Workflow 4: Rebuttal 📝 (reply to reviewers safely)
"Reviews are in. Help me draft a safe, grounded rebuttal."
Got reviews back? /rebuttal parses them, builds a strategy, and drafts a venue-compliant response:
- 📋 Parse — normalize reviews, validate venue rules (character limit, text-only, etc.)
- 🔍 Atomize — split each review into issue cards (type, severity, reviewer stance)
- 🗺️ Strategize — global themes, per-reviewer priorities, character budget, blocked claims
- 🧪 Evidence sprint — if
auto experiment: true, auto-run supplementary experiments via/experiment-bridge - ✍️ Draft — global opener + numbered per-reviewer responses + closing for meta-reviewer
- 🛡️ Safety check — 6 lints: coverage, provenance, commitment, tone, consistency, limit
- 🔬 GPT-5.6-Sol stress test — internal skeptical review of the draft
- 📄 Finalize — two outputs:
PASTE_READY.txt(exact character count) +REBUTTAL_DRAFT_rich.md(extended version for manual editing) - 🔄 Follow-up rounds — delta replies for reviewer discussions, technically escalating
Show W4 rebuttal flow diagram — parse reviews → strategy → optional evidence sprint → draft → GPT-5.6-Sol stress test → finalize 2 versions → follow-up rounds
┌─────────────────────────────────────────────────────────────────┐
│ Workflow 4: Rebuttal │
│ │
│ Reviews arrive │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Parse & │────▶│ Strategy │────▶│ Evidence │ │
│ │ atomize │ │ plan │ │ sprint │ │
│ │ reviews │ │ │ │ (optional)│ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Finalize │◀────│ GPT-5.6-Sol │◀────│ Draft │ │
│ │ 2 versions│ │ stress │ │ rebuttal │ │
│ │ │ │ test │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ PASTE_READY.txt (strict) + RICH.md (extended) │
│ │ │
│ ▼ │
│ Follow-up rounds (delta replies, per-reviewer threads) │
└─────────────────────────────────────────────────────────────────┘
Skills involved: rebuttal
💡 Quick mode:
/rebuttal — quick mode: truestops after parsing + strategy (Phase 0-3). See what reviewers want before committing to a full draft.
⚙️
VENUE,AUTO_EXPERIMENT,QUICK_MODE,MAX_STRESS_TEST_ROUNDSare configurable — see Customization.
Three safety gates — rebuttal will NOT finalize if any fails:
- 🔒 Provenance — every claim maps to paper/review/user-confirmed result. No fabrication.
- 🔒 Commitment — every promise is user-approved. No overpromising.
- 🔒 Coverage — every reviewer concern is tracked. Nothing disappears.
Workflow 5: Resubmit Pipeline 🔁 (port a paper to a new venue, text-only)
Port a polished paper from venue A → B under hard, non-overridable guardrails — no new experiments · no bib edits · no framework changes · never overwrites prior submissions — via physical isolation, a 5-layer anonymity check, soft-only audits, whitelist microedits, and a /kill-argument adversarial gate. Full flow + constraints → docs/RESUBMIT_AND_TALK.md
Workflow 6: Conference Talk Pipeline 🎤 (paper → slides → polish → audits)
/paper-talk turns an accepted paper into a talk: outline → /paper-slides (Beamer + PPTX + speaker notes + Q&A) → /slides-polish (per-page Codex visual pass) → optional conference-ready audit gate. Sister to /paper-writing / /paper-poster-html. Full flow → docs/RESUBMIT_AND_TALK.md
📚 Research Wiki — Persistent Research Memory
"Stop re-deriving. Start compounding." — inspired by Karpathy's LLM Wiki
Without the wiki, ARIS is stateless — every /idea-discovery starts from scratch. With the wiki, ARIS accumulates knowledge across the entire research lifecycle: papers read, ideas tested, experiments run, claims verified or invalidated.
The key insight: failed ideas are the most valuable memory. A researcher who knows what doesn't work generates better ideas than one starting from zero.
Setup:
> /research-wiki init # one-time, creates research-wiki/ in your project
That's it. Once initialized, the wiki works automatically.
Show the automatic wiki hooks — what fires at /research-lit, /idea-creator, /result-to-claim, plus the re-ideation nudge
| When | What happens | Wiki action |
|---|---|---|
/research-lit finds papers |
Papers auto-ingested | papers/<slug>.md created, edges added, query_pack rebuilt |
/idea-creator runs |
Reads wiki first | Failed ideas = banlist, gaps = search seeds, papers = known prior work |
/idea-creator finishes |
ALL ideas written back | Both recommended AND eliminated ideas → ideas/<id>.md |
/result-to-claim judges |
Results written back | Experiment page created, claim status updated (supported/invalidated) |
| 3+ ideas fail | Re-ideation suggested | "💡 Consider re-running /idea-creator — the wiki now knows what doesn't work" |
Show Research Wiki data model — Paper / Idea / Experiment / Claim entities and the typed graph edges that connect them
Four entity types:
| Entity | What it stores | Example |
|---|---|---|
| 📄 Paper | Structured summary: thesis, method, limitations, reusable ingredients | paper:chen2025_factorized_gap |
| 💡 Idea | Hypothesis, status (proposed/failed/succeeded), failure notes, lessons | idea:001 |
| 🧪 Experiment | Metrics, verdict, hardware, duration | exp:001 |
| 📋 Claim | Testable statement + evidence status (reported/supported/invalidated) | claim:C1 |
Typed relationships (stored in graph/edges.jsonl):
paper --extends--> paper idea --inspired_by--> paper
paper --contradicts--> paper idea --tested_by--> experiment
paper --addresses_gap--> gap experiment --supports--> claim
paper --supersedes--> paper experiment --invalidates--> claim
Show Research Wiki spiral-learning example and manual subcommands — failed ideas → better ideas across 3 rounds; ingest / query / update / lint / stats
Spiral learning in action:
Round 1: read 15 papers → wiki remembers → idea A → experiment → FAIL
wiki records: "A fails because OOM at batch>32, loss diverges"
Round 2: /idea-creator reads wiki → sees A failed → generates idea D (avoids A's trap)
→ experiment → PARTIAL SUCCESS
wiki records: "D works on small models, fails on large"
Round 3: /idea-creator reads wiki → knows A failed + D partial → generates idea F
(combines D's success with new approach) → experiment → SUCCESS 🎉
Subcommands:
/research-wiki init # initialize wiki
/research-wiki ingest "paper title" — arxiv: xxx # manually add a paper
/research-wiki query "topic" # rebuild query_pack.md
/research-wiki update idea:001 — outcome: negative # update entity
/research-wiki lint # health check (orphans, contradictions, stale claims)
/research-wiki stats # overview (paper/idea/experiment/claim counts)
🔒 Safe by design: All workflow hooks are guarded by
if research-wiki/ exists. No wiki = no impact. Zero dependencies (pure Python stdlib). You choose when to enable it.
Workflow M: Meta-Optimize 🧬 (ARIS optimizes itself)
"Analyze my usage patterns and improve your own skills."
Unlike Workflows 1–4 which optimize research artifacts (papers, code, experiments), Workflow M optimizes the harness itself — the SKILL.md instructions, default parameters, and convergence rules that govern how ARIS operates. Inspired by Meta-Harness (Lee et al., 2026).
Show Workflow M one-time setup and usage commands — Claude Code hook install, /meta-optimize variants (project / per-skill / --global / apply)
Setup (one-time, in normal terminal):
mkdir -p .claude .aris/meta tools/meta_opt
cp Auto-claude-code-research-in-sleep/templates/claude-hooks/meta_logging.json .claude/settings.json
cp Auto-claude-code-research-in-sleep/tools/meta_opt/*.sh tools/meta_opt/
chmod +x tools/meta_opt/*.sh
claude # hooks active immediately
Usage (after 5+ workflow runs):
> /meta-optimize # analyze current project
> /meta-optimize "auto-review-loop" # focus on one skill
> /meta-optimize --global # analyze trends across ALL projects
> /meta-optimize apply 1 # apply recommended change #1
How it works:
- 📊 Passive logging — Claude Code hooks silently record every skill invocation, tool call, failure, parameter override, and user prompt. Events are written to both project-level (
.aris/meta/events.jsonl) and global (~/.aris/meta/events.jsonl, with a"project"tag) logs. Zero user effort. - 🔍 Pattern analysis —
/meta-optimizereads the log and identifies:- Parameters users override most often (bad defaults)
- Tools that fail repeatedly in specific skills (missing error handling)
- Review score plateaus (convergence rules too loose/tight)
- Manual corrections users make (skill gaps)
- 🩹 Patch proposal — generates minimal diffs to target SKILL.md files with data-backed justifications
- 🔬 Reviewer gate — GPT-5.6-Sol xhigh reviews each patch: does the evidence support it? could it hurt other users?
- ✅ User approval — only applied with explicit user consent. All changes are logged and reversible.
Show Workflow M diagram and "what gets optimized" component table — event logs → SKILL.md patches → GPT-5.6-Sol review → user approval; prompts / defaults / convergence / error handling
┌─────────────────────────────────────────────────────────────────┐
│ Workflow M: Meta-Optimize │
│ │
│ Normal ARIS usage (W1-W4) │
│ │ (hooks log events passively) │
│ ▼ │
│ .aris/meta/events.jsonl │
│ │ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Analyze │────▶│ Propose │────▶│ GPT-5.6-Sol │ │
│ │ patterns │ │ SKILL.md │ │ reviews │ │
│ │ │ │ patches │ │ patch │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ▼ │
│ User approves? │
│ Yes → Apply │
│ No → Skip │
└─────────────────────────────────────────────────────────────────┘
What gets optimized (harness components):
| Component | Example |
|---|---|
| Skill prompts | Reviewer instructions, quality gates, step descriptions |
| Default parameters | difficulty, MAX_ROUNDS, threshold |
| Convergence rules | When to stop the review loop, retry counts |
| Error handling | Auto-debug patterns, failure recovery steps |
What does NOT get optimized: research artifacts (papers, code, experiments) — that's what W1–W4 do.
Skills involved: meta-optimize
💡 This is a maintenance workflow, not part of the W1→W1.5→W2→W3→W4 research pipeline. Run it periodically, like
git gcfor your research harness.
⚡ Effort Levels
Every skill takes — effort: lite | balanced | max | beast — scaling breadth/depth (papers · ideas · pilots · rounds · seeds · audit depth) from ~0.4× to ~5–8×; balanced is the default (zero change for existing users). What never changes at any level: Codex reasoning stays at its tier floor (regular xhigh; deep audits ultra), DBLP/CrossRef citations on, reviewer independence on, experiment integrity on. 📖 Full spec + per-skill counts → effort-contract.md
Assurance Gate (effort: max | beast)
A second axis, orthogonal to effort: assurance decides whether mandatory audits are load-bearing. lite/balanced ⇒ draft (audits non-blocking — current behavior, zero change); max/beast ⇒ submission (paper-writing Phase 6 force-runs /proof-checker + /paper-claim-audit + /citation-audit in fresh threads and refuses the Final Report if tools/verify_paper_audits.sh exits non-zero). Escape hatch: — effort: beast, assurance: draft. 📖 Full spec → assurance-contract.md
🧿 Optional: GPT-5.5 Pro via Oracle
Add — reviewer: oracle-pro to any reviewer-aware skill (/proof-checker, /research-review, /experiment-audit, /rebuttal, …) to route review through GPT-5.5 Pro — strongest reasoning for deep proof / code / experiment-design critique. Default stays Codex xhigh; Oracle not installed ⇒ graceful fallback + warning (zero impact). 📖 Setup + per-skill examples → reviewer-routing.md
9. ⚙️ Setup
📖 New to ARIS?
SETUP_GUIDE.md(中文) gives a prescriptive 6-step walkthrough for macOS local + remote Linux GPU server with Claude Code + Codex MCP — the recommended path. The section below is a quick reference; deeper GPU / customization / model-combo setup lives in the linked docs.
10.1 Prerequisites
- Claude Code installed
- (For review skills) Codex CLI installed and configured as MCP server:
npm install -g @openai/codex claude mcp add codex -s user -- codex mcp-server - (For Workflow 3: paper writing) LaTeX environment with
latexmkandpdfinfo:# macOS brew install --cask mactex # or: brew install basictex brew install poppler # provides pdfinfo # Ubuntu/Debian sudo apt install texlive-full latexmk poppler-utils # Verify latexmk --version && pdfinfo -vWindows (PowerShell): Install a TeX distribution using the MiKTeX Basic Installer or TeX Live for Windows. Install Poppler for Windows separately, add the directory containing
pdfinfo.exetoPATH, and open a new PowerShell window. Then verify:latexmk --version pdfinfo -vIf either command is not found, refresh the TeX distribution's package/path settings and check that the Poppler directory containing
pdfinfo.exeis onPATH. If you only need Workflow 1 & 2 (idea discovery + auto review), LaTeX is not required.
10.2 Install Skills
💡 Recommended: project-local flat symlink install (since 2026-04-20). Each ARIS skill is symlinked individually into
.claude/skills/<skill-name>, so Claude Code's slash-command discovery picks them up. A manifest at.aris/installed-skills.txttracks what ARIS installed — uninstall and reconcile only ever touch managed entries, never your own skills.🤖 Codex mirror route: keep Claude on
install_aris.sh/smart_update.sh. For Codex-native project installs, useinstall_aris_codex.sh; for copied Codex installs, usesmart_update_codex.sh.
# 1. Clone ARIS once to a stable location
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep.git ~/aris_repo
# 2. For each project that uses ARIS, attach via symlinks:
cd ~/your-paper-project
bash ~/aris_repo/tools/install_aris.sh
# → creates one symlink per skill: .claude/skills/<skill> → ~/aris_repo/skills/<skill>
# → writes manifest .aris/installed-skills.txt (tracks every entry ARIS installed)
# → updates managed CLAUDE.md ARIS block (best-effort, compare-and-swap)
# → re-runnable: rerun anytime to reconcile new/removed upstream skills
# 3. To update existing skills' content for ALL attached projects:
cd ~/aris_repo && git pull # symlinks resolve to live upstream — content updates automatically
# 3a. To pick up newly added or removed upstream skills, rerun the installer:
bash ~/aris_repo/tools/install_aris.sh ~/your-paper-project # adds new symlinks, removes broken ones
# Install only what you need (#366 selective install; a bare TTY run opens a checkbox picker):
bash ~/aris_repo/tools/install_aris.sh --list-groups # show the 10-group catalog
bash ~/aris_repo/tools/install_aris.sh --groups paper-core,lit-search # install by group
bash ~/aris_repo/tools/install_aris.sh --skills paper-writing # by skill; hard pipeline deps auto-included
bash ~/aris_repo/tools/install_aris.sh --exclude patent-pipeline # opt out (declined; never re-asked on update)
# On update, NEW upstream skills need per-skill confirmation; --add-new accepts all / --skip-new skips all
# Other useful flags:
bash ~/aris_repo/tools/install_aris.sh --dry-run # show plan, no changes
bash ~/aris_repo/tools/install_aris.sh --uninstall # remove only managed symlinks (per manifest)
bash ~/aris_repo/tools/install_aris.sh --from-old # migrate from old nested .claude/skills/aris/
# Windows (PowerShell, no WSL required; creates flat per-skill junctions):
.\tools\install_aris.ps1 C:\path\to\your-paper-project -Platform claude
.\tools\install_aris.ps1 C:\path\to\your-codex-project -Platform codex
Why "git pull" alone isn't enough for new/removed skills: the flat layout uses one symlink per skill, so upstream additions/deletions don't propagate until the installer is re-run. The trade-off bought us Claude Code's automatic slash-command discovery (which only scans one directory level deep).
Migrating from the old nested install (pre-2026-04-20)
If you previously installed via install_aris.sh (which created .claude/skills/aris/ as a single nested symlink) or via smart_update.sh --target-subdir .claude/skills/aris, your slash commands probably weren't being auto-discovered by Claude Code. Migrate to the flat layout:
# Symlink-style legacy install:
bash ~/aris_repo/tools/install_aris.sh ~/your-project --from-old
# Copy-style legacy install (with possible local edits — chose strategy explicitly):
bash ~/aris_repo/tools/install_aris.sh ~/your-project --from-old --migrate-copy keep-user
# → keeps your nested .claude/skills/aris/ copy intact alongside the new flat install
bash ~/aris_repo/tools/install_aris.sh ~/your-project --from-old --migrate-copy prefer-upstream
# → archives nested copy to .aris/legacy-copy-backup-<timestamp>/, then flattens
Alternative installs (advanced)
Project-local copy (no symlinks, useful for per-project skill edits):
mkdir -p ~/your-project/.claude/skills
bash ~/aris_repo/tools/smart_update.sh --project ~/your-project --apply
# Default --target-subdir is .claude/skills (flat), which is what Claude Code expects.
# (The old --target-subdir .claude/skills/aris is now deprecated — see migration block above.)
Global install (one copy in your home dir, available to every project):
mkdir -p ~/.claude/skills
cp -r ~/aris_repo/skills/* ~/.claude/skills/
# Update with: bash tools/smart_update.sh --apply
Global install increases the risk of skill name collisions with other globally-installed packs. Use only if you don't mix ARIS with Superpowers / OpenHands / etc. — otherwise prefer the project-local install above.
💡 New Claude Code versions may not auto-create
~/.claude/skills/. If using global install, create it first:mkdir -p ~/.claude/skills/. The symlink installer handles directory creation automatically.
Optional: Codex Plugin for Code Review
codex-plugin-cc provides additional Codex capabilities that ARIS auto-detects when installed:
# In Claude Code:
/plugin marketplace add openai/codex-plugin-cc
/plugin install codex@openai-codex
/reload-plugins
/codex:setup
Where ARIS uses the plugin:
| Skill | Workflow | What it does |
|---|---|---|
/codex:review |
Workflow 1.5 | Review experiment code before GPU deployment |
/codex:adversarial-review |
Workflow 1.5 | Adversarial code review (find edge cases, bugs) |
/codex:rescue |
Workflow 1.5 + 3 | Auto-debug rescue — when experiment or LaTeX compilation fails after 2 attempts, Codex independently diagnoses the root cause before the next retry |
All plugin features are optional — if not installed, ARIS falls back to Claude's own diagnosis. The plugin just adds a second pair of eyes.
Note: ARIS's core cross-model review (paper scoring, idea evaluation, rebuttal stress test) still uses Codex MCP, which allows custom prompts. The plugin cannot replace this.
10.3 Update Skills
cd Auto-claude-code-research-in-sleep
git pull
# 🧠 Smart update (recommended) — analyzes what's safe to update
bash tools/smart_update.sh # dry-run: shows what would change
bash tools/smart_update.sh --apply # apply: updates safe ones; NEW upstream skills prompt
# one-by-one on a TTY, or use --add-new / --skip-new
# Manual options (if you prefer):
# cp -r skills/* ~/.claude/skills/ # Option A: overwrite all
# cp -rn skills/* ~/.claude/skills/ # Option B: only add new, keep yours
# cp -r skills/experiment-bridge ~/.claude/skills/ # Option C: specific skill
💡 Smart update compares your local skills with upstream, detects personal customizations (server paths, API keys, etc.), and only updates skills that are safe to replace. Skills with your personal info are flagged for manual review.
10.4 Usage
# Workflow 1: Idea Discovery
> /idea-discovery "your research direction" # full pipeline
> /research-lit "topic" # just literature survey (all sources)
> /research-lit "topic" — sources: zotero, web # mix and match sources
> /research-lit "topic" — sources: deepxiv # DeepXiv-only progressive retrieval
> /research-lit "topic" — sources: exa # Exa AI-powered web search with content extraction
> /research-lit "topic" — arxiv download: true # also download top arXiv PDFs
> /arxiv "discrete diffusion" — download # standalone arXiv search + download
> /idea-creator "topic" # just brainstorm
# Workflow 2: Auto Research Loop
> /auto-review-loop "your paper topic" # review → fix → repeat
> /research-review "your paper" # single deep review
# Workflow 3: Paper Writing
> /paper-writing "NARRATIVE_REPORT.md" # full pipeline
> /paper-plan "NARRATIVE_REPORT.md" # just outline
> /paper-compile "paper/" # just compile
# Full Pipeline
> /research-pipeline "your research direction" # Workflow 1 → 2 → 3 end-to-end
# Supporting Skills
> /run-experiment train.py --lr 1e-4 --epochs 100
> /analyze-results figures/*.json
> /monitor-experiment server5
10.5 🌙 Auto-Allow for Overnight Runs (Optional)
Skip permission prompts on overnight runs — add a snippet to .claude/settings.local.json
To run the auto-review loop without clicking permission prompts, add to .claude/settings.local.json:
{
"permissions": {
"allow": [
"mcp__codex__codex",
"mcp__codex__codex-reply",
"Write",
"Edit",
"Skill(auto-review-loop)"
]
}
}
🖥️ GPU for Auto-Experiments (Optional)
When the reviewer says "run an ablation", Claude Code writes the script and runs it on your GPU — you just declare your server in CLAUDE.md. Three modes (Remote SSH · Local GPU · Vast.ai on-demand): config snippets + setup → docs/GPU_SETUP.md (Vast.ai deep-dive → Vast.ai guide). No GPU? Review/rewrite skills still work; experiment fixes are flagged for manual follow-up.
🔌 Integrations (Optional)
Plug your library / vault / notifications into ARIS — each auto-skips silently if unconfigured:
- Zotero — collections + annotations + BibTeX in
/research-lit(before web search). - Obsidian + arXiv — search your vault notes; arXiv is built-in, no setup.
- Feishu / Lark — mobile push + interactive approve/reject for overnight runs.
10. 🎛️ Customization
Skills are plain Markdown — fork and tune them. Per-skill environment variables (GPU target, code review, reviewer routing, human checkpoints, paper-writing knobs) and parameter pass-through live in docs/CUSTOMIZATION.md.
11. 🔀 Alternative Model Combinations
No Claude / OpenAI API? Swap in other providers — same cross-model architecture. ARIS ships 10 alternative routes (Z.ai GLM, Alibaba Kimi/Qwen/MiniMax, free DeepSeek-V3.1 via ModelScope, OpenRouter as a pin-one-of-many reviewer backend, Codex-as-executor with Claude/Gemini reviewers, Google Antigravity). Full routing table + per-route setup in docs/MODEL_COMBINATIONS.md.
12. 💬 Community
Domain-specific skills welcome! The core skills cover general research workflows, but every field has its own tools and patterns. We welcome PRs that add new skills for your domain — EDA, bioinformatics, robotics, HPC, or anything else. Just add a skills/your-skill/SKILL.md and open a PR. See dse-loop for an example.
Join the WeChat group for discussion on Claude Code + AI-driven research workflows:

13. 📖 Citation
If you use ARIS in your research, please cite:
@article{yang2026aris,
title={ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration},
author={Yang, Ruofeng and Li, Yongcan and Li, Shuai},
journal={arXiv preprint arXiv:2605.03042},
year={2026}
}
14. ⭐ Star History

15. 🙏 Acknowledgements
Inspired by — 🧪 AI Scientist (Sakana) · 📖 AutoResearch (Karpathy) · 🔭 FARS (Analemma) · 🎨 PaperBanana (PKU).
Core infra — Claude Code (execution backbone) · Codex CLI (cross-model review via MCP).
Integrations — Zotero (guide): zotero-mcp, Zotero. Obsidian (guide): mcpvault, obsidian-skills (by Obsidian CEO Steph Ango). Feishu/Lark (guide): feishu-claude-code, clawdbot-feishu, cc-connect, lark-openapi-mcp.
Paper-writing inspiration — claude-scholar · Research-Paper-Writing-Skills · baoyu-skills. Community — awesome-agent-skills (featured).
Platform adaptation — 🤖 @Falling-Flower (Codex CLI adaptation via spawn_agent) · 🔧 @No-518 (Codex skill maintenance) · 🖱️ @YecanLee (Cursor guide + local GPU docs) · 🏆 @DefanXue & @Monglitay (first ARIS community paper, CS conference 8/10).
Architecture & vision — 💡 @JingxuanKang: beyond code (training-check, result-to-claim, ablation-planner, watchdog, templates, session recovery), deeply shaped ARIS through discussions on compact mode, workflow state management, and the vision of autonomous research — many of today's core features (structured project files, context-aware session recovery) grew out of these conversations.
16. License
MIT
